
Most enterprise AI deployments hit the same wall. The proof-of-concept works beautifully. The chatbot answers clean, well-structured test questions with confidence. But six months into production, the cracks show: stale answers, missed context, and a support team still manually handling everything the AI was supposed to resolve.
The problem isn't the language model. It's the architecture underneath it.
In 2026, forward-thinking engineering and product teams are closing this gap by pairing AI agents with RAG (Retrieval-Augmented Generation). The combination turns static Q&A bots into goal-driven, self-correcting systems that actually complete tasks. This post breaks down how agentic RAG systems work, where they outperform traditional setups, and how to build them using frameworks like LangChain and LangGraph.
Why Traditional RAG Falls Short in Enterprise Settings

RAG was a meaningful step forward. Instead of relying solely on a model's training data, you connect it to a live knowledge base: internal documents, SOPs, product catalogs, CRM notes. The model retrieves relevant chunks and grounds its response in real data. Hallucinations drop. Accuracy improves.
But traditional RAG is still a passive system. A user asks a question, the pipeline retrieves context, the model generates a response, and the loop closes. There's no ability to re-query when the first retrieval misses, no mechanism to break a complex task into steps, and no tool-calling to actually act on what's been retrieved.
Industry research published in early 2026 frames this clearly: RAG failures typically surface at identifiable pipeline stages, such as poor retrieval or weak source ranking, but the system has no way to correct itself mid-run. For single, well-scoped questions, that's acceptable. For multi-step enterprise workflows, compliance checks, research summarization, support case resolution, it falls short fast.
This is the gap agentic RAG fills.
💡 Pro Tip: Identify your workflow's decision points first
Before retrofitting RAG onto any enterprise process, map every decision or judgment call a human currently makes mid-task. Those are the exact points where an agentic layer adds the most value over a traditional retrieval pipeline.
What Makes Agentic RAG Different
Agentic RAG embeds an autonomous AI agent into the retrieval pipeline. Instead of retrieving once and generating once, the agent plans, retrieves, evaluates what it got, decides whether to re-query or switch tools, and iterates toward a goal.
The three core capabilities that separate agentic RAG from standard RAG are:
- Multi-step reasoning: The agent breaks a complex task into subtasks, completing each one before moving to the next. A compliance audit that previously required six manual steps can now be handled in a single agentic workflow.
- Tool orchestration: The agent isn't limited to reading documents. It can call APIs, write to databases, trigger downstream automations, and route outputs to other agents. RAG, in this framework, acts as one tool among many, providing external knowledge access the same way a calculator or weather API would.
- Adaptive retrieval: If the first retrieval round returns low-confidence chunks, the agent reformulates the query and retries. It can also route different question types to different retrieval strategies: vector search for semantic questions, graph traversal for relationship queries, keyword search for precise lookups.
Building AI Agents with RAG and LangChain
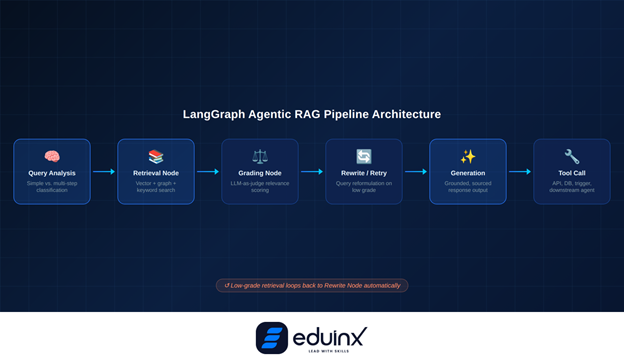
LangGraph, part of the LangChain ecosystem, has become the go-to framework for agentic RAG in production. It models agents as explicit state machines: each node in the graph handles a specific task (retrieve, evaluate, rewrite query, call tool, generate), and edges define conditional transitions between them.
Here's what a minimal agentic RAG loop looks like in LangGraph:
- Query analysis node: The agent receives a user query and determines whether it's simple (single retrieval) or complex (multi-step reasoning required).
- Retrieval node: Executes a vector search against your knowledge base. Returns ranked document chunks.
- Grading node: An LLM-as-judge evaluates whether the retrieved chunks are actually relevant to the query.
- Rewrite/retry node: If the grading node scores retrieval poorly, the agent rewrites the query and loops back.
- Generation node: Once retrieval passes the grade threshold, the agent generates a grounded response.
- Tool call node: Optional. If the task requires an action (updating a ticket, sending a summary, querying a live API), the agent handles it here.
If you're exploring how these orchestration approaches play out in a product context, this primer on AI orchestration in product development is worth reading alongside this post.
The Role of Memory in Self-Learning Workflows
Short-term memory (conversation history within a session) is table stakes. What separates self-learning enterprise workflows is persistent memory: the agent's ability to remember outcomes across sessions and use them to improve future retrievals.
This is where knowledge graphs come in. Rather than storing flat document chunks in a vector store alone, enterprises are increasingly pairing vector databases with graph databases (Neo4j, Weaviate's graph layer, or similar). The graph captures relationships between entities: products, clauses, customers, cases, regulations. When an agent traverses this graph, it can follow relationship edges to find connected information that a pure vector search would miss.
Leading AI Agents for Enterprises in 2026
The market for enterprise agentic AI has matured quickly. Several platforms have moved from early-adopter curiosity to production infrastructure:
- LangGraph (LangChain): The default choice for teams that need explicit control over agent state, branching logic, and human-in-the-loop approval steps. Open-source core with an optional paid platform for deployment and monitoring.
- AutoGen (Microsoft): Role-based multi-agent framework, particularly effective when workflows require multiple specialized agents collaborating: a research agent, a summarization agent, and an output-formatting agent working in sequence.
- CrewAI: Well-suited for teams that want predefined agent roles without heavy custom orchestration. The open-source core remains free; enterprise tooling including UI, RBAC, and deployments is paid.
- ServiceNow AI Agents: Purpose-built for IT and enterprise service workflows. Handles ticket triage, knowledge retrieval, and escalation logic out of the box, reducing the need for custom orchestration.
Across production deployments, the non-framework choices that most determine success are observability tooling (LangSmith, Langfuse, or Arize for traces and evaluations), guardrails, and a clear deployment story. Teams that underestimate this piece are the ones whose agents stall after a successful demo.
Where Agentic RAG Delivers the Most Enterprise Value

Not every workflow is a fit. Agentic RAG is most valuable where tasks are: repeatable, knowledge-dependent, multi-step, and currently handled through a mix of document lookup and human judgment.
The strongest use cases today:
- Compliance and regulatory review: An agent builds a knowledge graph linking regulations, clauses, and internal policies. When new regulations arrive, it cross-references connected clauses, flags risks, and generates a compliance brief with auditable source trails, work that previously took a team of analysts days.
- Customer support resolution: Support agents retrieve past case resolutions, product documentation, and account history simultaneously, then propose a fix that worked in similar past cases. This reduces costly escalations and turns customer support into a proactive function rather than a reactive one.
- Internal knowledge management: Instead of employees hunting through SharePoint or Confluence for the right policy document, an agentic RAG system retrieves, synthesizes, and surfaces exactly what they need, across multiple knowledge bases, in one response.
The career implications here are real. Engineers who understand how to build and evaluate agentic RAG pipelines, retrieval quality metrics, agent evaluation frameworks, observability tooling are in significant demand. If you're building toward an AI/ML engineering role, understanding the evaluation layer is just as important as knowing how to build the retrieval pipeline itself. The Eduinx piece on building a data science career with production AI skills covers how teams are structuring these roles today.
🧠 Pro Tip: Evaluate retrieval quality before you evaluate generation quality
Most teams spend their debugging time on the LLM's output. The smarter move is to instrument your retrieval layer first, log chunk relevance scores, retrieval miss rates, and query rewrite frequency. If retrieval is poor, no amount of prompt engineering on the generation side will fix it.
What "Self-Learning" Actually Means in Practice
The phrase "self-learning" gets overused. In the context of agentic RAG, it has a specific and achievable meaning: the system improves retrieval and response quality over time based on feedback signals.
This happens through several mechanisms:
- Human-in-the-loop corrections: An agent surfaces a draft response; a domain expert approves, edits, or rejects it. That feedback is stored and used to fine-tune the reranking model or adjust retrieval parameters.
- Automated quality loops: An LLM-as-judge evaluates every agent output against a rubric. Low-scoring outputs trigger a query rewrite and retry in the same session; patterns of low-scoring outputs flag configuration issues for human review.
- Knowledge base updates: When new documents or data are ingested, the knowledge graph is updated, entity relationships are re-established, and outdated chunks are flagged for removal. The agent retrieves from a continuously fresh knowledge base rather than a static snapshot.
By 2026, 85% of enterprises are projected to adopt hybrid RAG systems combining vector and graph databases, largely because self-updating knowledge graphs are the most practical way to keep retrieval accurate at scale.
"Production-ready agentic RAG demands orchestration layers, validation logic, tool resilience, and real-world observability. The payoff? Agents that don't just deliver answers, they complete tasks, integrate across systems, and evolve with feedback."
— Toloka AI Engineering Blog, 2026
From Proof-of-Concept to Production
The gap between a working prototype and a production-ready agentic RAG system is wider than most teams expect. A few principles that separate the teams who get there:
- Define success metrics before you build: nDCG@10 for retrieval quality, task completion rate for agent success, and cost-per-query for sustainability. If you can't measure it, you can't improve it.
- Build observability in from day one: LangSmith, Langfuse, or Arize let you trace every node transition, retrieval round, and tool call. Teams that add this as an afterthought spend twice as long debugging production issues.
- Govern tool access carefully: Every tool an agent can call is a potential failure mode. Use role-based access controls (RBAC) to limit which agents can write to which systems, and build explicit human approval steps for high-stakes actions.
If you're working in a product management capacity and thinking about how to prioritize and sequence this kind of infrastructure investment, the Eduinx post on agentic workflows in product development frames the roadmap questions well.
Conclusion
AI agents with RAG aren't a feature you add to an existing system. They're a different category of architecture, one that turns language models from answer machines into goal-driven systems capable of completing real enterprise tasks. The organizations getting the most out of this in 2026 are the ones who started with a clear understanding of what their workflows actually need: adaptive retrieval, multi-step reasoning, and feedback loops that make the system measurably better over time.
Frequently Asked Questions (FAQs)
1. What is an agentic RAG and how is it different from traditional RAG?
Agentic RAG integrates with the autonomous AI agents into the process of retrieval. Unlike traditional RAG, which usually follows a simple retrieve-and-generate workflow, Agentic RAG can plan, retrieve, evaluate results, retry failed searches, use different tools, and perform multi-step reasoning tasks autonomously. It can be self-correct if the retrieval quality is low by re-querying or changing strategies without human intervention.
2. Why does traditional RAG fail in enterprise settings?
Traditional RAG is a passive pipeline and there is no mechanism to self-correct when it either fails to retrieve, or retrieval does not produce rich enough context. For the more complex, multi-step enterprise workflows like compliance checks or support resolution, a single retrieval-generation loop cannot succeed.
Traditional RAG can work well for simple Q&A, policy lookup, FAQ bots, and document search. It starts failing when the workflow requires planning, multiple searches, tool use, validation, or action-taking.
3. What are the 3 essential abilities of agentic RAG?
Multi-step reasoning (subtasks), tool orchestration (API calls to different tools, writing to databases, triggering automations etc.), and adaptive retrieval (query reformulation, retrying to low-confidence results). Together, these turn a passive Q&A bot into a goal-driven system.
4. How to use LangGraph for building agentic RAG pipelines?
LangGraph models agents as state machines, with each node performing a specific operation: retrieving, grading, rewriting, generating or calling a tool, with edges representing conditional transitions between nodes. This provides teams explicit control over the branching logic, retries, and human-in-the-loop approval steps.
5. Which AI agent frameworks will be best for enterprise use in 2026?
The LangGraph suits teams needing fine-grained state control; AutoGen is great for multi-agent collaboration; CrewAI provides pre-defined roles with limited setup; and ServiceNow AI Agents handles IT workflows out of the box. Observability tooling - LangSmith, Langfuse, or Arize - is equally critical regardless of framework.


Rishabh Dev Choudhary
Share on Social Platform:
Subscribe to Our Newsletter
Recommended Articles

AI Product Managers: Roles, Responsibilities, and Future Scope
Did you know that a highly skilled product manager has the ability to increase
Learn More

Generative AI: A Deep Dive
Did you know that 75% of gen AI users are looking to
Learn More