
Did you know that recently, Databricks built an RAG agent that can handle all kinds of enterprise searches? With Autonomous AI Agents emerging as the new operating system for enterprise intelligence, industries have moved from static automation to reasoning, acting, and adapting systems. Agentic AI in Retrieval-Augmented Generation (RAG) and a multi-agent RAG system with AI orchestration frameworks have revolutionized how LL-powered agents function. With intelligent retrieval systems driving the growth for AI powered organizations, the scope for growth is immense for RAG engineers and gen AI experts.
A brief on Agentic RAG
An AI agent is a self-sufficient entity that can sense its surroundings, make decisions, and take actions to fulfill its objectives. Agentic AI enhances this independence by integrating reasoning and planning, allowing agents to act proactively rather than just reactively. This capability enables AI to independently decide its subsequent actions without waiting for directives.
Conversely, RAG (Retrieval-Augmented Generation) connects static AI models with the ever-evolving environment. Rather than depending exclusively on pre-existing knowledge, RAG systems actively fetch current information from sources such as APIs or databases, which allows them to produce contextually precise and pertinent responses. I consider RAG particularly beneficial in sectors like healthcare, education, and business, where access to real-time data is essential.
How does Agentic RAG work?
Agentic RAG recognizes what is necessary to accomplish a task without waiting for direct instructions. For example, if it comes across an incomplete dataset or a question that needs more context, it independently identifies the missing components and seeks them out. This autonomy enables it to act as a proactive problem-solver.
In contrast to conventional models that depend on fixed, pre-trained knowledge, agentic RAG actively accesses real-time data. It employs sophisticated tools such as APIs, databases, and knowledge graphs to retrieve the most pertinent and current information. Whether it pertains to contemporary market trends or the latest research findings, this guarantees that its outputs are both timely and precise.
The data retrieved is not simply presented as it is—instead, agentic RAG processes and synthesizes it into a cohesive response. It merges external information with its internal knowledge to produce outputs that are accurate, meaningful, and contextually relevant. This ability elevates it from being just an information retriever to an intelligent assistant.
The system integrates feedback into its operations, allowing it to enhance its responses and adjust to changing tasks. Each iteration makes Agentic RAG more intelligent and efficient, similar to how a human hones their skills through experience. This feedback loop guarantees sustained performance improvement.
Difference between Agentic RAG and Traditional RAG
Traditional RAG systems function in a reactive manner, heavily relying on predefined queries and explicit human direction throughout the data retrieval process. Their dependence on structured input and inability to stray from given instructions limits their effectiveness. Essentially, they act as static tools for information retrieval, extracting data solely based on the specific query presented. This inflexible method restricts their adaptability and problem-solving abilities.
A fitting analogy for traditional RAG is visiting a library with a precise list of books—you must know exactly what you seek, as the system will not provide assistance beyond your specified instructions.
Whereas Autonomous AI Agents and RAG systems are built to be proactive and self-sufficient. By continuously assessing the context and user intent, these systems can independently gather and integrate pertinent information from various sources, including real-time data feeds and external APIs. This proactive strategy allows them to produce thorough and contextually appropriate responses without the need for explicit human involvement.
Using the same analogy, agentic RAG resembles employing a research assistant who not only locates the best resources but also organizes and summarizes them into a well-crafted report, greatly reducing time and effort.
Building Autonomous Retrieval and Generation Pipelines
A RAG pipeline is the framework that executes all necessary steps to enable Retrieval-Augmented Generation in a production setting. It manages data ingestion, streaming, cleaning, chunking, embedding, indexing, retrieval, prompt assembly, orchestration, and monitoring, allowing a large language model (LLM) to utilize retrieved context when formulating a response.
The RAG pipeline links the model to the information it requires at the time of the query. When a user poses a question, the pipeline fetches the most pertinent documents, prepares that text as context, and incorporates it into the prompt, enabling the model to generate an answer based on the retrieved content rather than solely on its training data.
- ● Data ingestion and preparation – This involves gathering raw data, cleaning it, and organizing it into embeddable segments.
- ● Embedding and indexing – This process converts text into vector representations and stores them in a vector database for rapid similarity searches.
- ● Retrieval and prompting – This step involves obtaining the most relevant documents for a specific query and integrating that context into the model’s prompt prior to generation.
- ● Orchestration and workflow management – This entails coordinating retrieval, generation, and dependencies throughout the system.
- ● Evaluation and monitoring – This includes assessing retrieval relevance, answer quality, and system performance over time.
Collectively, these elements create the infrastructure that provides the model with the context it relies on during generation. If the data feeding the pipeline becomes outdated or incomplete, the quality of retrieval diminishes, leading to less reliable answers from the model. A production pipeline addresses this issue by ensuring that retrieval remains consistent and aligned with current data.
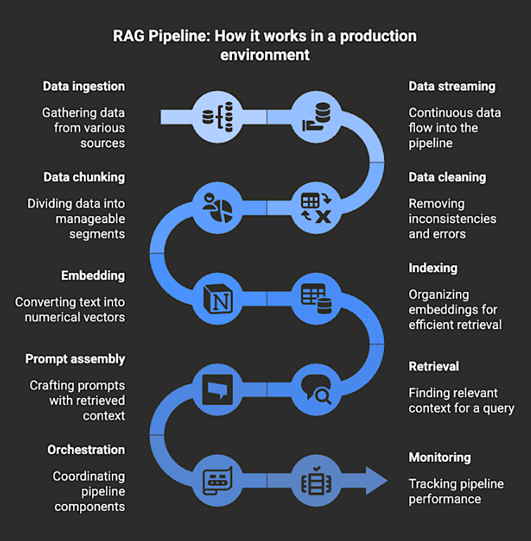
RAG Pipeline: Source
Benefits of Building an RAG Pipeline
Hallucination happens when an AI makes assumptions to fill in gaps rather than relying on factual information. RAG pipelines mitigate this issue by ensuring that every response is anchored in the retrieved context. Prior to generating text, the system gathers pertinent documents or records, allowing it to provide evidence-based responses instead of relying on memory. For instance, a retail chatbot utilizing RAG will always reference the most current return policy or product information rather than fabricating details to appear knowledgeable.
In rapidly evolving industries, information is subject to swift changes: consider product listings, stock prices, compliance updates, or market trends. Static models are unable to keep pace. RAG pipelines address this challenge by linking models to data stores that are continuously updated, whether they are internal knowledge bases or live web data streams. This results in responses that reflect the latest available information.
Organizations frequently function within specialized fields that involve unique terminology, data security compliance requirements, and decision-making logic that general-purpose LLMs do not inherently grasp. RAG pipelines allow AI systems to dynamically integrate domain-specific knowledge bases such as internal documents, research papers, product manuals, or regulatory filings. Consequently, the model can reason accurately within that specific context.
With the rise in demand for implementing agentic AI in RAG systems, the job market for RAG engineers is booming. At Eduinx, we provide a holistic learning experience through a virtual classroom environment. Our mentors are non academicians who have over a decade of industry relevant experience. We also provide placement assistance and help you land your dream job. We guide you in completing your capstone project and help you learn complex concepts through a hands-on approach. Get in touch with us to know more about our post graduate program in generative AI.



