
For the better part of three years, Retrieval-Augmented Generation (RAG) has been the quiet workforce of enterprise-level AI. It is powering everything from contract querying to internal knowledge assistants. The context window has exploded from mere 8000 tokens to millions and beyond, while a large part of the AI community declared RAG dead.
But, as it turns out, that declaration was wrong.
Expanding context windows have no role in replacing RAG. Rather, they unlocked a far more powerful version of the RAG. Expanding the context windows did not replace the RAG, rather it unlocked a far more powerful version of it. In this blog, we explain what this actually means for enterprise teams building AI systems in 2026.
How Context Windows Went From 8K to 10 Million Tokens
This expansion did not happen by accident, rather, three architectural breakthroughs made it possible. These were Flash Attention, Ring Attention, and KV Cache Optimization. Understanding these breakthroughs even at a surface level can help explain why long context vs RAG 2026 is less of a competition and more of a convergence.
Flash Attention tackled one of the most stubborn bottlenecks in transformer architecture. It was the way models read and write data between GPU memory layers. Flash Attention dramatically reduced the memory overhead and made training on longer sequences practical without sacrificing model quality. It did so by reorganizing how attention calculations are performed.
Ring Attention solved the problem of scale even further. Instead of forcing a single device to process an entire long sequence, Ring Attention distributes the workload across devices connected in a ring shape. This allows LLM context window size comparison to look radically different from that of just two years ago. It was facilitated with sizes scaling linearly with available hardware and windows exceeding 100 million tokens.
KV Cache Optimization addressed the memory cost of running these models at inference time. Techniques like cache eviction, quantization, and hybrid memory offloading to CPU or SSD made it possible to serve long context LLM enterprise deployment scenarios without even requiring data center-grade infrastructure for every query.
In 2026, models like Gemini 3 Pro are offering 10 million token windows, while Llama 4 Scout matches these numbers as an open-source option. Even mid-tiered models can now comfortably handle 128,000 to 200,000 tokens as baseline. However, the infrastructure for long-context reasoning still exists.
Why Bigger Windows Do Not Automatically Mean Better Results
Here is where the nuance begins, and where a lot of enterprise teams get caught off guard.
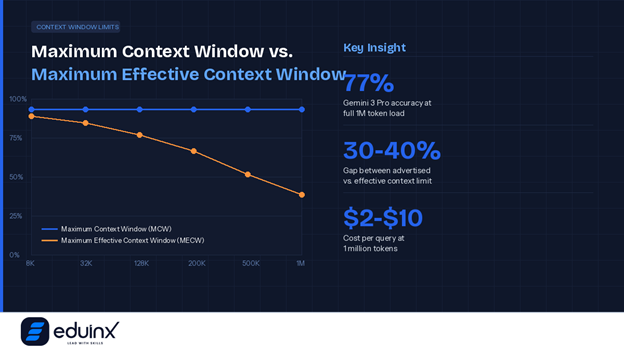
There is an important distinction between a model's Maximum Context Window and its Maximum Effective Context Window. The first is what the marketing materials advertise. The second is the point beyond which feeding the model more tokens actually starts to hurt output quality rather than help it. Understanding context window vs token limit explained is not just a technical detail — it is a business-critical distinction for anyone making infrastructure decisions.
The most well-documented failure mode is called Lost in the Middle. Research has consistently shown that LLMs tend to pay closer attention to information positioned at the very beginning or end of a long prompt. Content buried in the middle of a massive context gets underweighted during generation, producing a U-shaped performance curve where accuracy degrades for anything sitting in that vast middle section.
Then there is context rot, a phenomenon where performance begins degrading noticeably beyond a certain threshold even within a model's advertised limit. Claude 3 users have reported meaningful quality drops past 200,000 tokens despite the model supporting more. Gemini 3 Pro maintains around 77% accuracy at its full one-million-token load, with competitors performing worse.
There is also a cost dimension that gets overlooked in technical discussions. At one million tokens with current pricing, a single query can cost between two and ten dollars. Scale that to thousands of daily queries across an enterprise and the monthly bill becomes a serious budget conversation.
This is not an argument against long-context models. It is an argument for using them with precision rather than as a blunt instrument. And precision, as it happens, is exactly what RAG is built to provide.
💡 Pro Tip: Do not rely solely on an LLM’s advertised context window limit when designing enterprise systems. Always benchmark your specific use case to identify where quality degradation begins. The effective limit is often 30-40% lower than the marketed figure. Often, this gap directly affects the reliability of your outputs in production.
The Limitations of Naive RAG, And Why Advanced RAG is Different
Before exploring what advanced RAG can do, it is worth being honest about what basic RAG cannot.
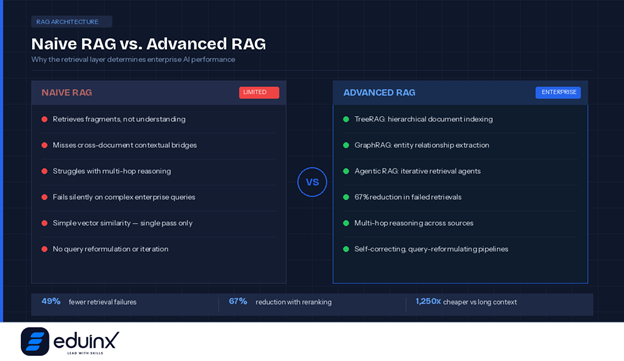
Naive RAG, the kind most early implementations relied on, works by breaking documents into chunks, embedding those chunks as vectors, and retrieving the ones most similar to a user query. It was a genuine breakthrough when context windows were small and enterprises needed a way to give LLMs access to external knowledge without retraining them.
But naive RAG has real failure points. It retrieves fragments, not understanding. When a query requires connecting information across multiple documents, basic vector similarity search often misses the contextual bridges between them. It struggles with multi-hop reasoning, where the answer to a question depends on a chain of related facts spread across different sources. It can also fail silently, returning confident-sounding answers built on retrieved chunks that are technically relevant but contextually incomplete.
Anthropic's own research put a hard number on how significant this problem is. Alex Albert, Head of Developer Relations at Anthropic, stated:
"Contextual Retrieval reduces incorrect chunk retrieval rates by up to 67%. When combined with prompt caching, it may be one of the best techniques there is for implementing retrieval in RAG apps."
— Alex Albert, Head of Developer Relations, Anthropic
A 67 percent reduction in retrieval failures is not a minor optimization. It is the difference between a system that occasionally misleads users and one that enterprise teams can actually trust.
These are not flaws in the RAG architecture itself. They are the limitations of a specific, simplified implementation of it. The architecture has evolved considerably, and the expansion of context windows is a significant reason why.
💡 Pro Tip: If your RAG system is underperforming, the problem is almost always in the retrieval layer, not the generation layer. Before switching models, audit your chunking strategy, check whether chunks carry sufficient surrounding context, and test hybrid retrieval combining semantic search with BM25. Anthropic's Contextual Retrieval research shows that fixing the retrieval step alone can cut failure rates by 49 to 67 percent.
Advanced RAG Use Cases Unlocked by Expanding Context Windows
The three most significant advances in RAG architecture each benefit directly from larger context windows, and each opens up retrieval augmented generation enterprise use cases that were simply not viable before.
TreeRAG uses an LLM to build a hierarchical index of a document corpus, structured like a directory tree. When a query comes in, the system locates the most relevant branch first and then expands outward to pull in parent nodes and sibling documents for richer surrounding context. The larger the context window, the more of that surrounding context can be passed to the model at once, dramatically improving the coherence of responses on complex queries. Enterprise legal teams reviewing contract repositories are seeing real gains here — the model can locate a specific clause and immediately understand the broader agreement it lives within.
GraphRAG takes a different approach by extracting entities and relationships from documents and mapping them into a knowledge graph. This allows the system to surface connections between information fragments that are semantically related but physically distant in the original source material. For LLM enterprise knowledge base RAG deployments with overlapping domains — think a consulting firm's internal research library or a pharmaceutical company's clinical documentation — GraphRAG retrieves answers that basic vector search would never surface. Expanding context windows mean that more of the relevant graph neighborhood can be included in each generation call.
Agentic RAG represents the frontier of agentic RAG enterprise accuracy. Rather than treating retrieval as a single step, Agentic RAG embeds autonomous agents into the pipeline. These agents evaluate whether retrieved documents actually answer the query, reformulate the search if they do not, try multiple retrieval strategies in parallel, and iterate until they have sufficient confidence in the context before passing anything to the generation model. In financial research workflows, an Agentic RAG system can autonomously pull earnings data, analyst commentary, and macroeconomic context from separate sources before synthesizing a coherent briefing — something no single retrieval pass could accomplish.
The broader value here extends to LLM enterprise document analysis use cases across industries — from healthcare systems querying clinical trial data to manufacturing firms interrogating maintenance records across decades of documentation.
💡 Pro Tip: Before investing in complex RAG infrastructure, run a simple test. If your total knowledge base is under 200,000 tokens, try full-context prompting with prompt caching first. Anthropic's own research suggests this can be faster and cheaper than building a retrieval pipeline for smaller corpora — and it eliminates chunking errors entirely at that scale.
Long Context and RAG: The Hybrid Architecture Winning in 2026
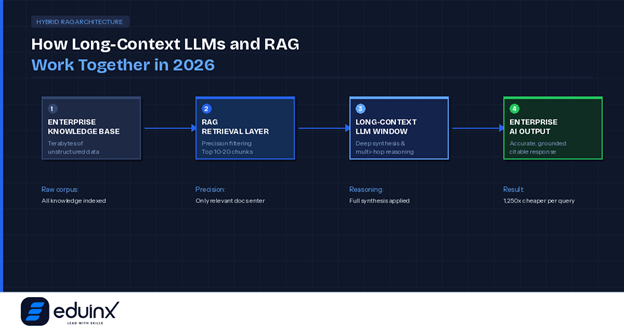
The most sophisticated enterprise implementations in 2026 are not choosing between long-context LLMs and RAG. They are using both in sequence, with each doing what it does best. The hybrid RAG long context architecture is where the real performance gains are happening.
The pattern looks like this: RAG handles the retrieval layer with precision, identifying and extracting the most relevant documents from a potentially vast and dynamic corpus. That retrieved material then gets passed into a long-context model, which performs deep synthesis, cross-document reasoning, and multi-hop analysis across the full set of retrieved content.
This approach solves the two biggest problems simultaneously. RAG keeps token costs controlled by ensuring that only relevant material enters the context window rather than the entire corpus. The long-context model then handles the reasoning depth that fragmented chunk-by-chunk retrieval could never support.
Anthropic's research offers a clear practical guideline on where the boundary sits:
"If your knowledge base is smaller than 200,000 tokens — about 500 pages of material — you can just include the entire knowledge base in the prompt with no need for RAG or similar methods."
— Anthropic Research Team
Beyond that threshold, the hybrid approach consistently outperforms both pure long context LLM enterprise deployment and naive RAG systems on quality, cost, and response reliability — particularly across legal, financial, and knowledge management workflows.
💡 Pro Tip: When building a hybrid RAG plus long-context system, be disciplined about what enters the context window. Use RAG to retrieve the top 10 to 20 most relevant chunks, then structure them so the highest-relevance content sits at the beginning and end of the prompt. This directly counters the "Lost in the Middle" phenomenon and can meaningfully improve response quality without increasing token costs.
Conclusion
Expanding context windows have not made retrieval augmented generation enterprise use cases obsolete. They have made them better, more capable, and more suited to the kind of complex, multi-source reasoning that enterprise AI applications actually demand.
The organizations getting the most value from AI in 2026 are not the ones who picked a side in the long context vs RAG 2026 debate. They are the ones who recognized early that the two are complementary, built hybrid RAG long context architecture systems that combine retrieval precision with long-context reasoning depth, and started investing in context engineering AI agents 2026 as an organizational capability.
The context window is bigger than it has ever been. What you put inside it still matters more than ever.



