Did you know that the new GraphRAG works beyond vector only RAG? IT bridges the gap between complex enterprise data and functional AI agents, making it a highly reliable tool.
Also, Google’s AI edge offers robust support for on-device RAG, making it an ideal choice for working professionals and leadership in the industry. Also, recently, Coveo, a Canadian software company has introduced RAG as a service for AWS agentic AI services. These recent developments have driven the increase in demand for gen AI professionals who are well versed in RAG applications. It is time for you to gear up and learn image and text integration for next-level RAG applications as it will open the door for different opportunities across several industries. Let us now look into multimodal LLMs and their influence on Next-generation RAG systems.
Evolution of RAG
AI is advancing beyond mere text, with Multimodal Large Language Models leading this transformation. But what is multimodal RAG, and why is it increasingly essential in contemporary AI? In simple terms, it enables AI models to effortlessly combine and comprehend various data types such as text, images, audio, and more, resulting in more enriched, context-sensitive outputs.
In contrast to conventional RAG, multimodal systems generate embeddings within a cohesive space: CNNs are responsible for processing images, transformers take care of text, and dedicated audio models handle sound.
Retrieval Augmented Generation (RAG) began as a model focused solely on text, allowing AI to access documents and answer questions based on that content. Over time, RAG has developed to incorporate images, charts, and various other data types, leading to the emergence of Multimodal Large Language Models in RAG. Cutting-edge AI models are now crafted to handle multiple forms of data.
Frameworks like LangChain and LlamaIndex assist AI developers in building retrieval pipelines and engaging with application programming interfaces (APIs). Nowadays, thanks to advancements in AI technology, agentic RAG can independently retrieve and generate information across different modalities, resulting in a more intelligent and self-sufficient AI experience.
Working of Multimodal RAG
In multimodal systems, the RAG architecture typically comprises three stages: generation, retrieval, and knowledge preparation.
Multimodal Knowledge Preparation
Data encoded for various modalities is derived from an embedding as follows:
Text is processed through transformers to capture context and semantics. Images are encoded using CNNs or vision-language models to represent visual characteristics. Audio is transformed into embeddings with models like wav2vec, which generate vectors that represent the audio.
Contrastive learning plays a crucial role in aligning pairs of data from different modalities, such as an image and its corresponding caption, ensuring these items remain close in the system's memory. When a user later poses a text-based question to the AI, it can utilize the retrieved image or audio to formulate a response.
Query Processing and Retrieval
When embeddings are stored in vector databases, queries are performed to identify the nearest neighbors. Vector databases are designed for low-latency searches and operations over extensive datasets.
Conventional multimodal RAG pipelines employ frameworks like LangChain to execute queries, retrieve pertinent data that can be summarized, and transform this relevant data to prepare it for the generative phase.
Context Building and Generation
Following retrieval, the system integrates the related inputs. In early fusion, various inputs would be combined into a single representation, whereas in late fusion, each input type would retain its individual representation until the final stages of the process.
Subsequently, the multimodal LLM produces the response, which may take the form of text, an image with a text caption, or an audio segment. This approach also reduces errors and enhances the quality of the output.
Approaches in Multimodal RAG
- ● Text retrieval with multimodal generation: This method retrieves information through text embeddings while producing output in its original format.
- ● True multi-modal retrieval: All modalities are integrated into a common embedding space, enabling support for multimodal reasoning.
- ● Agentic RAG: These systems autonomously determine what to retrieve and how to generate contextually appropriate output from the retrieved information.
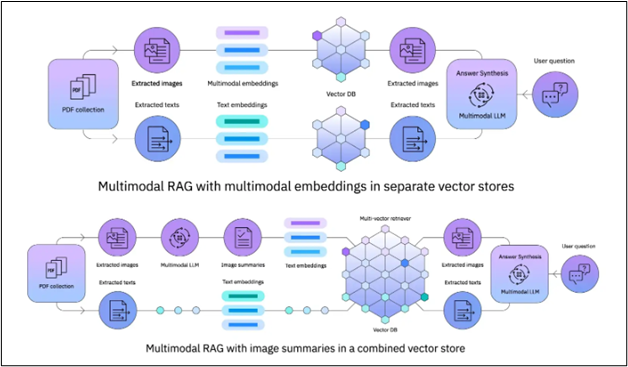
The below illustration depicts two different architectural strategies for the implementation of Multimodal Retrieval-Augmented Generation (RAG) systems. These systems improve a Large Language Model's (LLM) capacity to respond to user inquiries by incorporating and comprehending data from both textual and visual sources.
Applications of Multimodal RAG
Multimodal RAG is implemented across industries that rely on image and video as their primary source of business. Here are a few applications of multimodal RAG.
- ● Visual Question Answering: Users can pose questions regarding an image or video, and the AI generates a text response grounded in the visual material.
- ● Healthcare Knowledge Systems: Multimodal RAG can evaluate a medical image or patient records to deliver precise insights.
- ● Enterprise Search Engines: When users submit queries, the AI retrieves pertinent documents, presentations, or diagrams to enhance productivity.
- ● Customer Support: AI support systems can simultaneously respond to inquiries with both text and images, as well as provide audio replies.
- ● In real-world applications, multimodal RAG has surpassed single-modality systems in terms of accuracy and relevance, particularly when integrating information from text and images. This capability is exemplified in generative AI models such as GPT-4V and LLaVA.
How is Multimodal RAG Integrated in Gen AI
For companies, multimodal RAG represents not just a technological advancement; it serves as a competitive advantage. Businesses can integrate their multimodal RAG systems into their operations via APIs, allowing for automated knowledge retrieval and improved decision-making.
- ● Utilizing RAG frameworks like LangChain and LlamaIndex to manage pipelines.
- ● Refining multimodal LLMs with data from specific domains.
- ● Developing agentic RAG systems that utilize reasoning and operate independently within defined limits.
- ● Acquiring skills as an AI or prompt engineer allows organizations to maximize their return on investment and unlock the capabilities of multimodal RAG.
Future of Multimodal RAG
The rise of multimodal RAG indicates its growing application in diverse sectors such as healthcare, finance, education, and content creation. It is anticipated that multimodal LLMs will enhance their accuracy, while agentic RAG will be increasingly utilized to facilitate autonomous reasoning. Retrieval-augmented generation is expected to integrate into enterprise AI strategies, and APIs will broaden to enable applications across different platforms.
Increased Jobs for Gen AI Engineers
Multimodal RAG improves generative AI by integrating text, images, audio, and additional elements to generate accurate, context-sensitive results. It employs CNNs, vision-language transformers, and multimodal LLMs to effectively engage with intricate multimodal prompts. Its impact spans from healthcare to corporate knowledge and multimedia searches, transforming how individuals perceive AI. As the industry progresses, AI engineers and specialists in generative prompts will be essential in developing intelligent systems. Here are a few recent developments on next-level RAG applications.
- ● RAG empowers organizations to navigate this generational shift by leveraging their own data assets on a large scale. It democratizes expertise, minimizes silos, and enables any employee to function like a domain expert, providing a significant competitive advantage in the knowledge economy.
- ● RealRAG improves text-to-image generative models (such as Flux and Stable Diffusion V3) by sourcing real-world images. By juxtaposing generated images with retrieved examples, the system addresses knowledge gaps to enhance realism. It yields more lifelike image outputs and elevates the quality of visual content. It proves particularly beneficial for product design and medical imaging, where precise visual representations are crucial.
- ● CoRAG dissects queries into sub-questions and retrieves information in a sequential manner. It modifies the depth and breadth of retrieval according to the complexity of the query and reformulates queries as needed.
- ● VideoRAG is capable of managing extremely lengthy video content without sacrificing accuracy. Its dual-channel architecture delivers detailed, context-rich summaries of video data.
Are you an aspiring gen AI engineer looking to make a mark in the industry? Look no further than Eduinx, as a leading edtech institute in India, we provide a classroom-based learning approach that focuses on industry-relevant applications. Our mentors are non-academicians with over a decade of experience across industries. Take up our postgraduate program in Gen AI and learn all about RAG applications and multimodal LLMs. We also provide placement assistance, helping you land your dream job. Get in touch with us for more information on our courses!



