
Introduction
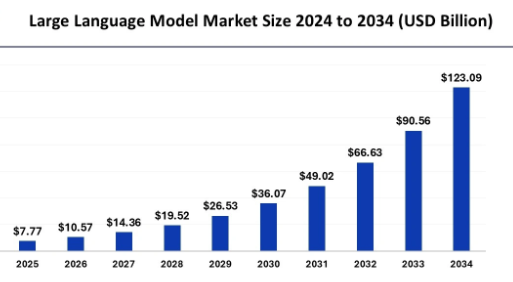
Did you know that the global Large Language Models (LLM) market is expected to reach $259.82 billion by 2030? Making LLMs the largest-growing solution used in generative AI and other AI-powered applications. LLMs have transformed the field of natural language processing as they are used in powering applications like chatbots, translators, and content generation systems. However, if you need to understand how LLMs work, you need to understand their core architecture, training processes, and core algorithms for performing complicated tasks. Here’s a deep dive into large language models for a better understanding.
- ● What is an LLM and how do they work?
- ● Transformer Architecture and its Core Components
- ● Training and Fine Tuning LLMs
- ● Text Generation and Sampling Methods
- ● Supporting Technologies: Vector Databases
- ● Tokenization and Embeddings
- ● Applications of LLMs
What is an LLM and how do they Work?
An LLM is a machine learning model which is trained on a vast amount of textual data. These models are also powered by deep learning algorithms which help in performing a variety of tasks such as translation, summarization, FAQs, and other specific language rules and regulations as well. A unique characteristic of LLM is its ability to process long sequences of text by focusing on relationships between words, sentences, and context across a vast amount of data.
Transformer Architecture and its Core Components
LLMs are built with a transformer-based architecture, enabling them to be integrated with any system and process long sequences of text with a focus on functioning relationships between words, sentences, and context across vast data. LLMs are usually built with BERT and GPT. Transformer architecture is the foundation of LLMs as it replaces older architecture like Recurrent Neural Networks (RNNs) and Long Term Memory (LTM) models. Here are some of the essential components of LLMs.
- ● Self-attention mechanism: In this, the LLM model focuses on different parts of the input text by assigning weights to each token in a sequence by gauging the relevance of each word used in a sentence.
- ● Positional Encoding: As transformers do not process words in a sequential manner like RNNs, positional encoding is used to provide information about the relative positions of tokens in the input sequence.
- ● Feed-forward layers: Data is passed through different feed-forward layers that refine the information.
- ● Multi-headed attention: Rather than computing a single attention score for each token, transformers use multiple heads to compute attention in parallel. The model can capture different attributes of the relationships between words.
Training and Fine Tuning LLMs
LLMS are typically trained on large datasets of text and code with unsupervised learning. The model is not informed of what the correct output is for each input. This model predicts the next world in a sentence or the next line of code according to the core context. The model is pre-trained on a large volume of text to know general language representations. Once the pre-training is done, LLMs can be fine-tuned for specific tasks that involve training the model on a smaller, task-specific dataset that is catered to a specific domain or application. This process is done with fine-tuning.
Text Generation and Sampling Methods
In text generation, the model predicts the next word in a sequence by considering the previous word. This is done by using a technique called autoregressive generation. This model converts and puts text into a sequence of embeddings where each word or token is mapped to a high-dimensional vector which captures the core meaning. While sampling the next token, text generation can be used to lead to repetitive or generic outputs. Here are different types of sampling methods.
- ● Greedy Search: Chooses the token with the highest probability at each step, resulting in repetitive or generic outputs.
- ● Beam Search: Maintains multiple candidate sequences at every step by using different possibilities to find the most likely sequence.
- ● Top-k Sampling: Restricts the next choice to the most probable tokens.
- ● Top-p (Nucleus) sampling: Takes tokens from the smallest set.
Supporting Technologies: Vector Databases
Storing and retrieving information is also a pivotal part of ensuring the similarity of searches and ensuring consistency. Vector databases are used for storing and retrieving high-dimensional vectors, which are the numerical representations of words or tokens generated by LLMs. For instance, when an LLM processes a sentence, it converts each word into a high-dimensional vector which captures the core semantic meaning of the words. Vector databases are used in recommendation systems like search engines to help in finding documents which have related content and are conversational.
Tokenization and Embeddings
Breaking down text and data are a core part of LLMs. In order to feed textual data into a neural network, it needs to be finely broken down into words or sub-words depending on the tokenizer used. LLMs use sub-word tokenization where unseen words are split into smaller chunks, this allows the model to handle a large vocabulary effectively. For instance, the word beautiful can be split into ‘beauty’ and ‘ful’. Once the tokenization is complete, each token is mapped to a high-dimensional vector space called embeddings. These embedding vectors represent the meaning of the tokens with similar vectors. Embeddings are usually learnt during the training period and help understand the meaning of words in different contexts.
Applications of LLMs
Now that you have understood the core workings of a large language model, it is essential for you to know how LLMs are used in real-world scenarios. As an AI product manager or a generative AI developer, you need to know how LLMs are used across different industries. Here are some common applications of LLMs across industries.
- ● Generating content for blogs, articles, and marketing copy
- ● Powering conversational chatbots like Siri or Alexa
- ● Helping software generate code snippets
- ● Translating multiple languages like Google Translate
- ● Extracting emotions or opinions from text in customer service or social media monitoring in sentiment analysis
Are you an aspiring data scientist, a generative AI developer, or an AI product manager? Eduinx has all the resources that you need to establish a strong foothold in these fields regardless of the industry that you choose. Our mentors help you learn all about large language models AI and machine learning concepts through a holistic hands-on practical approach. You can learn how to pre-train large datasets and fine-tune them for specific applications. This can help in achieving impressive results through a variety of NLP tasks. At Eduinx, we help you achieve your career goals through 360-degree career support and perform a capstone project, which will help you stand out from the competition and become the most sought-after resource.


