
The emergence of artificial intelligence has brought enterprises to a pivotal point: Should they allocate resources to Large Language Models (LLMs) for their versatility or to Small Language Models (SLMs) for their efficiency? This dilemma has become increasingly important as companies seek to find a balance between cost, performance, and specific task requirements. In this article, we will examine the distinctions, applications, and strategic consequences of SLMs and LLMs, assisting enterprises in making well-informed choices.
Large Language Models such as GPT-4 have led the way in AI advancements with their extensive capabilities, managing a wide range of tasks from creative writing to complex reasoning. Nevertheless, these models entail considerable computational expenses, necessitating substantial infrastructure and energy consumption. However, Small Language Models are rising as a practical alternative, providing domain-specific accuracy, cost-effectiveness, and reduced latency. For enterprises facing budget constraints and specialized needs, SLMs offer a transformative opportunity.
A Brief on SLM vs LLM
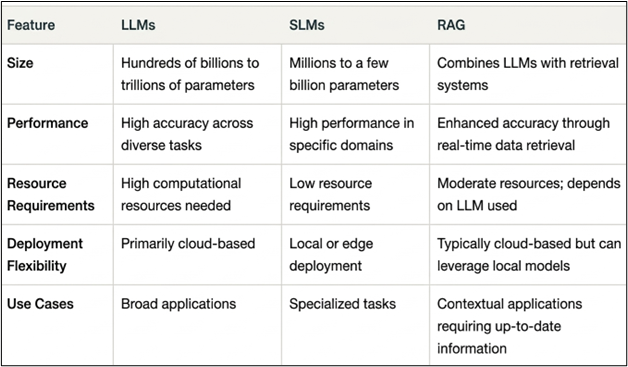
Small Language Models signify a crucial re-evaluation of the architecture of AI systems for practical applications. While large language models like GPT-4 showcase remarkable general capabilities with their 1.76 trillion parameters, small language models usually function within the range of 1 million to 20 billion parameters, concentrating on specialized tasks with exceptional efficiency.
The transition towards small language models is motivated by the practical needs of enterprises rather than just theoretical potential. Industry analysis indicates that 68% of businesses that implemented small language models experienced enhanced model accuracy and quicker return on investment compared to their large language model counterparts, which require fine-tuning for specific domains, thereby minimizing hallucinations and boosting task-specific accuracy.

Advantages of SLMs
SLMs are thriving due to their competitive performance and ability to be deployed without additional costs. They are monumental in being flexible to cater to varying compliance needs.
- Parameter Efficiency: Small language models provide competitive performance with 10 to 100 times fewer parameters than large language models, allowing for deployment on standard hardware without the need for specialized infrastructure.
- Speed Optimization: Small language models can process 150 to 300 tokens per second, in contrast to the 50 to 100 tokens per second of large language models, offering near real-time response capabilities that are vital for interactive applications.
- Deployment Flexibility: In contrast to cloud-reliant large language models, small language models can operate on edge devices, mobile platforms, and on-premises infrastructure, thus meeting data sovereignty and compliance needs.
What do Industries Adopt?
Experts recommend that the future involves the integration of LLMs and SLMs. Organizations can leverage LLMs for broad tasks and SLMs for specialized applications, striking a balance between flexibility and effectiveness. Ece Kamar, an AI executive at Microsoft, emphasizes that SLMs are well-suited for edge computing, whereas LLMs perform best in cloud environments.
By implementing a hybrid approach, companies can enhance their cost efficiency, performance, and compliance, developing smart solutions customized to their requirements. RAG embodies a hybrid strategy that merges the generative strengths of LLMs with information retrieval methods. This approach improves the model's capacity to deliver precise and contextually appropriate responses by sourcing information from external knowledge repositories. RAG proves to be especially beneficial in areas such as customer support systems, academic research assistants, and AI-powered fact-checking tools, where precision and relevance are of utmost importance.
Fine tuning is the key! Adoption and Specialization
Modern RAG has evolved beyond merely executing a basic vector search. To enhance the efficiency of these systems for both SLMs and LLMs, developers are concentrating on three essential technical pillars:
- Semantic Precision through Fine-Tuning: As previously mentioned, fine-tuning embedding models enables hyper-accurate retrieval. When the retriever comprehends the specific "language" of a sector—whether it’s genomic research or financial derivatives—the model needs less context to deliver a correct answer, thus conserving token usage.
- Context Compression & Ranking: Rather than inputting a large volume of "noisy" documents into a model, efficient RAG systems employ advanced reranking algorithms. These tools highlight only the most pertinent, high-signal information, allowing the model to handle less data while producing superior results.
- Adaptive Model Routing: The most advanced architectures now incorporate "router" agents. A straightforward query is directed to an SLM (cost-effective), while intricate, nuanced analysis is assigned to an LLM (reasoning-intensive). This dynamic switching optimizes performance while ensuring strict budget management.
Rise of Efficient RAG Systems through SLMs and LLMs
The emergence of effective RAG serves as the ultimate link between "AI potential" and "AI productivity." By separating the model's intelligence from its knowledge, companies can:
- Minimize Latency: Quicker retrieval and processing facilitate real-time, conversational AI interactions.
- Guarantee Compliance: More compact, specialized models are simpler to audit and manage, making them suitable for regulated sectors such as healthcare and finance.
- Maximize ROI: By employing the appropriate model for each specific task—driven by an efficient RAG system—businesses are finally witnessing the "measurable impact" they have sought since the inception of generative AI.
Whether you are scaling a large language model to address global strategies or implementing a network of small language models to streamline thousands of local processes, the effectiveness of your RAG system is the true indicator of your AI’s success.
Now that you have understood the nuances of SLMs vs LLMs and how efficient RAG systems help transform operations. You need to know how to implement them in your business a Eduinx leading edtech institute in India, gives you a hands-on overview and in-depth understanding of RAG systems through our generative AI course. Whether you are a working professional looking for a breakthrough in your career or a business owner looking to implement RAG systems in your organization, we guide you through a practical approach in learning through both virtual and offline classrooms. Get placement support and guidance at Eduinx
Frequently Asked Questions
How are SLM and LLM different in AI?
Small Language Models (SLMs) refer to smaller models trained to perform a specific task or for a particular domain, containing a lot fewer parameters than LLMs. The Large Language Models (LLMs) are the models trained on a huge dataset for performing a wide variety of tasks with a general scope. While LLMs generalize widely, SLMs exchange efficiency and economy of computation.
What are the real-world use cases of SLM and LLM?
LLMs, which are used for general-purpose tasks such as writing, coding, and reasoning, include models like GPT-4, Claude, Gemini Ultra. SLMs are on - device assistants, domain specific chatbots and embedded apps include Microsoft’s Phi-3, Meta LLaMA 3B, Google’s Gemma 2B, etc.
How does RAG work with LLM and SLM?
Retrieval-Augmented Generation, RAG, improves both SLMs and LLMs by obtaining relevant external information before generating a response thereby, avoiding hallucinations. SLMs and LLMs in combination enable an efficient and scalable AI pipeline where SLMs could be used for cost effective and fast retrieval-based tasks, while LLMs could be utilized for complex reasoning tasks.
What is adaptive model routing in RAG systems?
Advanced RAG architectures implement a 'router' agent that directs straightforward queries to a cost - effective SLM and complex, analytical tasks to LLMs, optimizing performance while enforcing a strict budget management across all query types.
How does fine-tuning boost RAG performance?
Fine-tuning the embedding model enables hyper accurate retrieval by teaching the model to learn the specific language of a sector-whether genomic research or financial derivatives. If the retriever knows a domain's terminology it means the model needs to understand even less context to produce a correct answer and save tokens.



