
Generative AI has moved from a research curiosity to a commercial force in just a few years. Models can now write legal briefs, compose music, generate photorealistic images, and replicate voices with startling accuracy. That power comes with serious questions that professionals and organisations can no longer defer: Who owns what AI creates? How do we verify what is real? And what does responsible generative AI look like in practice?
These are not abstract philosophical debates. They are live business, legal, and reputational challenges for anyone building products with AI, working in data science, or making decisions about AI adoption in 2026 and beyond.
The Copyright Problem at the Heart of Generative AI Training
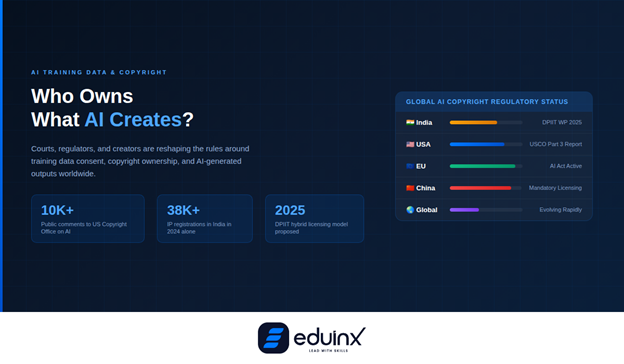
Every large language model and image generator was trained on data, and a vast amount of that data was scraped from the internet without explicit permission from creators. The legal and ethical fallout from that reality is now playing out in courtrooms across the globe.
In March 2025, the US Court of Appeals for the DC Circuit ruled in Thaler v. Perlmutter that copyright protection requires human authorship, firmly rejecting the idea that AI-generated content can itself be copyrighted. That settled one question but opened several more: if a model was trained on copyrighted works without consent, are its outputs tainted? And who bears liability?
The US Copyright Office published Part 3 of its AI report in May 2025 specifically addressing AI training data, while the EU's AI Act continues to require transparency disclosures for training datasets used in general-purpose AI models. The Generative AI Copyright Disclosure Act, introduced in the US Congress in 2024, would compel companies to publicly disclose the datasets powering their systems, giving creators clearer grounds to contest misuse.
In India, the situation is equally active. In November 2024, Asian News International (ANI) sued OpenAI in the Delhi High Court , alleging that training on ANI's content without permission constitutes infringement. India's Department for Promotion of Industry and Internal Trade (DPIIT) responded by constituting a committee in April 2025 to examine these issues and, in December 2025, published its first working paper proposing a hybrid licensing model. This would allow AI firms access to publicly available copyrighted content while channeling royalties to rights holders through a government-designated body, the Copyright Royalties Collective for AI Training (CRCAT).
Under Section 52 of India's Copyright Act, the fair dealing exception covers non-commercial research, which may not extend to AI companies training commercial models. The Indian AI Governance Guidelines released in November 2025 by MeitY explicitly acknowledge that copyright law may need amendment to accommodate large-scale AI training, while still protecting creators. For anyone building AI products in India or for Indian markets, this is the landscape to watch closely.
🎯 Pro Tip: Stay Ahead of Training Data Disclosure Requirements
Before deploying or fine-tuning any generative AI model, audit its model card for training data provenance. Models that document dataset sources and consent practices are significantly lower compliance risk, especially if your business operates across India, the EU, or the US. When regulatory disclosure mandates arrive, organisations with documented data lineage will adapt far faster than those starting from scratch.
Authenticity in Crisis: The Deepfake and Synthetic Content Problem

Copyright is a legal and structural challenge. Authenticity is a social one, and in some ways more urgent.
The volume of synthetic media online is growing at a rate that detection tools cannot match. From approximately half a million deepfake videos shared on social media in 2023, projections estimate up to 8 million by 2025. Research from UNESCO confirms that humans cannot consistently distinguish AI-generated voices from real ones. Deloitte projects that generative AI could drive US fraud losses from $12.3 billion in 2023 to $40 billion by 2027, a 32% annual growth rate.
The risks are not hypothetical. In January 2024, fraudsters used deepfake technology to impersonate a company's CFO on a video call, tricking an employee into transferring $25 million. Over 6% of fraud incidents now involve deepfakes, and synthetic identity fraud is encountered by 46% of fraud specialists.
The authenticity crisis runs deeper than fraud. When realistic fakes are easy to produce, genuine recordings become undeniable. Researchers call this the "liar's dividend": accused individuals can claim that authentic footage is fabricated, and audiences, having seen convincing fakes, are predisposed to believe the denial. This erodes trust in media, institutional communication, and digital evidence at scale.
For professionals building AI-powered products, this means authenticity is no longer a nice-to-have feature: it is a product requirement. Technologies like C2PA (Coalition for Content Provenance and Authenticity) watermarking and cryptographic provenance tracking are becoming the foundation of trustworthy AI content pipelines. China's Cyberspace Administration already mandates visible watermarks and identity authentication for synthetic content. The EU AI Act includes similar disclosure requirements for AI-generated media.
"The challenge is not just detecting fakes — it's rebuilding the conditions under which trust is possible at all."
— UNESCO, Deepfakes and the Crisis of Knowing 2025 (source)
Understanding the responsible use of synthetic data in AI systems is directly connected to this challenge. If you want to understand how synthetic data can be used ethically to improve model accuracy without scraping the internet, our primer on synthetic data and ML model accuracy covers the technical and ethical dimensions of that tradeoff.
🔍 Pro Tip: Build Provenance into Your AI Content Workflow
If your product generates text, images, audio, or video using generative AI, implement provenance metadata from day one. Tools like the C2PA standard allow you to cryptographically sign AI-generated assets so that downstream platforms, editors, and users can verify their origin. This protects your organisation legally and positions your brand as trustworthy in an era of rampant synthetic media.
What Responsible Generative AI Actually Looks Like

Ethics in AI is often framed as a checklist: bias audits, explainability scores, fairness metrics. Those matter, but responsible generative AI requires something more structural: accountability built into the system design rather than bolted on after deployment.
Consent, Transparency, and Data Governance
Responsible AI governance starts with how training data is acquired and documented. India's Digital Personal Data Protection Act 2023 (DPDP) is now tethered to the AI Governance Guidelines, meaning AI systems processing personal data must embed privacy by design. "Publicly available" data cannot be assumed to be freely usable. Consent, purpose limitation, and data minimisation apply even to foundation model training.
Transparency extends to users. If an output is AI-generated, that fact should be disclosed clearly, particularly in journalism, education, legal, and healthcare contexts. This is not just an ethical norm: it is becoming a regulatory requirement in multiple jurisdictions.
Human Oversight as a Design Principle
The US Copyright Office's ruling that copyright requires human authorship has a practical implication: the more creative input a human contributes to an AI-assisted work, selecting, editing, arranging, and directing, the stronger the protection. Responsible AI deployment therefore means keeping humans meaningfully in the loop, not just as a liability hedge but as a quality and accountability mechanism.
This aligns with what strong AI governance frameworks emphasise. MeitY's November 2025 Guidelines are explicit: human-centric design and human oversight are non-negotiable principles. For product managers and data scientists, this means designing workflows where AI recommends and humans decide, rather than AI deciding and humans ratify.
Understanding how AI governance frameworks translate into product decisions is well-covered in our breakdown of responsible AI governance for data science teams, which walks through frameworks like NIST AI RMF and the EU AI Act in practical terms.
Building an AI Governance Framework for Your Organisation
A usable AI governance framework for a team building with generative AI should address four things:
- Data provenance: Know where your training or retrieval data comes from, whether licences permit commercial use, and what personal data it contains.
- Output accountability: Define who reviews AI outputs before they are published, actioned, or served to end users. In high-stakes domains, this review should be mandatory, not optional.
- Transparency and disclosure: Establish a policy for when and how AI involvement in content creation will be disclosed to users, clients, or the public.
- Incident response: Have a plan for when something goes wrong, whether that is a hallucinated output causing harm, a copyright complaint, or a deepfake misusing your brand.
These are not theoretical governance frameworks. They are the practical difference between an AI deployment that scales with trust and one that runs into a regulatory or reputational wall.
🧠 Pro Tip: Make Ethics Part of Your AI Product Evaluation Criteria
When evaluating generative AI tools or models for your stack, ask vendors directly: What is the training data provenance? Is it licensed for commercial use? What content safety filters are in place? How is bias monitored post-deployment? Vendors who cannot answer these questions clearly represent a compliance risk. This question set also prepares you for enterprise procurement conversations, where legal and security teams will ask the same things.
What This Means for AI and Data Science Careers
Professionals who understand the ethics and governance layer of generative AI are increasingly rare and valuable. Most technical roles are oversubscribed with candidates who can build and train models. Far fewer can navigate the regulatory environment, advise on responsible deployment, or design governance frameworks that satisfy both legal and product requirements.
India's AI market is maturing rapidly. The DPIIT, MeitY, and major courts are all actively shaping the rules. Professionals who follow these developments and can translate them into actionable product or compliance decisions have a genuine edge. This is not soft skills. It is a technical and legal literacy that most data science curricula do not yet cover well.
If you are working toward a career in AI product management, understanding how agentic AI systems are being governed is equally important. The overview of agentic AI execution and decision-making explores how autonomous AI systems in product management tools are raising accountability questions that mirror the generative AI governance challenges discussed here.
Conclusion
Generative AI ethics is not a philosophical sidebar. It is a central competency for anyone building, deploying, or managing AI systems in 2026 and beyond. Copyright ambiguity, authenticity threats, and governance gaps are not problems someone else will solve before they affect you. The organisations and professionals who build responsible practices now, around data provenance, transparency, human oversight, and incident accountability, are the ones who will be trusted with more.
The regulatory environment is moving. India, the EU, and the US are all drafting and enforcing rules that will reshape how generative AI is built and deployed. Staying informed and building ethical practices into your workflow from the start is no longer optional. It is the foundation of sustainable AI work.



