
Real-world data is messy, expensive, and often dangerously incomplete. Healthcare records are locked behind privacy walls. Fraud datasets have one fraudulent transaction for every ten thousand legitimate ones. Computer vision models need edge cases that never happen in the wild. If you are building serious machine learning models today, waiting for perfect real-world data is not a strategy. It is a bottleneck.
Synthetic data changes that equation. By generating artificial datasets that mirror the statistical patterns of real data, teams are now training faster, reducing bias, and pushing model performance into territory that real-world data alone could not reach. This is not a workaround. For many of the world's most demanding AI applications, synthetic data has become the primary strategy.
What Is Synthetic Data and Why Does It Matter Now
Synthetic data is artificially generated data that replicates the structure, distribution, and patterns of real datasets without containing any actual real-world records. The methods behind it range from classical statistical sampling to deep learning techniques like Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and now large language models.
Here is what makes this moment different: the tools have matured dramatically. A few years ago, generating synthetic tabular data that was statistically faithful enough to actually train a production model was a research-level problem. Today, platforms like Gretel, K2view, and Synthesis AI have turned it into a repeatable workflow.
The numbers back this up. Estimates suggest that more than 60% of data used for AI applications in 2024 was synthetic, and this proportion is growing. The synthetic tabular dataset market alone was valued at $1.36 billion in 2024 and is projected to hit $6.73 billion by 2029, growing at a compound annual rate of nearly 38%. That is not speculative investment. That is adoption at scale.
Three core problems are driving this growth: data scarcity, privacy regulations, and the high cost of real-world data labeling. Synthetic data addresses all three simultaneously.
💡 Pro Tip: Start with the data gap, not the tool.
Before choosing a synthetic data platform, identify exactly where your training data fails: too few minority class examples, missing edge cases, or privacy compliance requirements. The right generation technique depends entirely on the type of gap you are filling.
How Synthetic Data Improves Machine Learning Model Performance

This is where data scientists often get skeptical. Does artificially generated data actually make models better, or does it just make datasets bigger?
The evidence points clearly toward better. Here is how it works across the most common modeling challenges.
Fixing Class Imbalance
Class imbalance is one of the most persistent problems in applied machine learning. Fraud detection, disease diagnosis, equipment failure prediction, most high-stakes classification tasks have wildly skewed class distributions. Traditional approaches like SMOTE (Synthetic Minority Over-sampling Technique) help, but they have real limitations. SMOTE interpolates between existing minority examples, which means it cannot generate examples outside the distribution of observed data. When the minority class is genuinely underrepresented, SMOTE simply creates variations of the same limited signal.
Modern synthetic data generation using GANs or diffusion models goes further. Instead of interpolating between existing points, generative models learn the underlying probability distribution of the minority class and sample genuinely new examples from it. Research using the SYNAuG framework, which applies pre-trained diffusion models to balance class distributions, showed consistent improvement in both accuracy and fairness metrics across diverse datasets, including cases where traditional methods failed entirely.
Financial services firms using synthetic data augmentation for fraud detection have reported accuracy improvements of up to 19%. That is not a marginal gain. In fraud prevention, that difference has direct, measurable business value.
Handling Rare and Edge-Case Scenarios
Real data collection is inherently biased toward common events. Autonomous driving datasets have thousands of recordings of normal highway driving and relatively few examples of a pedestrian stepping off a curb in low-visibility rain at 11pm. Medical imaging datasets are sparse on rare conditions because rare conditions are, by definition, rare.
Synthetic data fills this gap by design. Nvidia's Cosmos and Isaac GR00T platforms, announced at GTC 2025, use simulation-driven training to generate the kinds of edge cases that real-world data collection simply cannot produce at scale. This is not supplementary to their training pipeline. It is central to it.
For data scientists working in computer vision, NLP, or time-series forecasting, the principle is the same: identify the scenarios your model has never seen and generate synthetic examples of them before those scenarios show up in production.
Accelerating Model Iteration Without Data Bottlenecks
Production data pipelines have latency. Getting access to new labeled data, especially in regulated industries like finance or healthcare, can take weeks or months. Synthetic data pipelines have no such bottleneck. You can generate a fresh dataset tuned to test a new hypothesis in hours.
This matters enormously for iteration speed. Teams that integrate synthetic data generation into their modeling workflow effectively decouple model development from data procurement. That is a structural advantage, especially for smaller teams competing against larger organizations with more data assets.
Compressing decision cycles in AI-driven product development has become one of the most important competitive levers available, and fast data iteration is a key part of that equation.
🎯 Pro Tip: Use synthetic data for stress-testing before production.
Before deploying any model, generate a synthetic test set that deliberately over-represents your failure modes: rare events, adversarial inputs, demographic edge cases. If your model cannot handle synthetic stress scenarios, it will not handle real ones.
The Main Data Simulation Techniques Used in Practice

Understanding which generation technique fits which problem is the practical skill that separates senior data scientists from the rest. Here is a working overview.
Generative Adversarial Networks (GANs)
GANs remain the most widely used deep learning approach for synthetic data. A generator network creates fake data samples; a discriminator network tries to distinguish them from real ones. The two networks train together in an adversarial loop until the generated data is statistically indistinguishable from real data.
Conditional GANs (cGANs) extend this by allowing you to specify conditions on the generated output, like generating examples of a specific class label or demographic group. This is particularly useful for targeted augmentation of underrepresented groups in your dataset.
Variational Autoencoders (VAEs)
VAEs learn a compressed latent representation of your data and then sample from that latent space to generate new examples. They are generally more stable to train than GANs and tend to produce smoother distributions. VAEs are especially effective for tabular data and sequential data like time series.
Research on fine-tuning language models on imbalanced datasets showed that combining VAEs with BERT embeddings to generate synthetic training examples significantly improved classification performance compared to models trained without augmentation. The approach works because it generates synthetic examples in the embedding space of the model itself, ensuring the synthetic data is semantically coherent rather than just statistically similar.
Diffusion Models
Diffusion models have emerged as the state-of-the-art approach for image synthesis and are increasingly applied to tabular and multimodal data. They work by learning to reverse a gradual noising process, effectively learning the data distribution from the ground up. For computer vision tasks, diffusion-based synthetic data has substantially closed the performance gap with models trained on real images.
Statistical Simulation
Not every use case needs deep learning. For structured tabular data, statistical methods that model marginal distributions and correlations between features, like the Synthetic Data Vault (SDV) library, are often faster, more interpretable, and sufficient for the task. SDV has been downloaded more than 7 million times and is used by approximately 10% of global Fortune 500 companies for exactly this reason. The same pattern of combining retrieval and generation pipelines that is reshaping agentic RAG frameworks is now appearing in synthetic data workflows, where LLMs generate context-aware training examples on demand.
Real-World Applications Across Industries
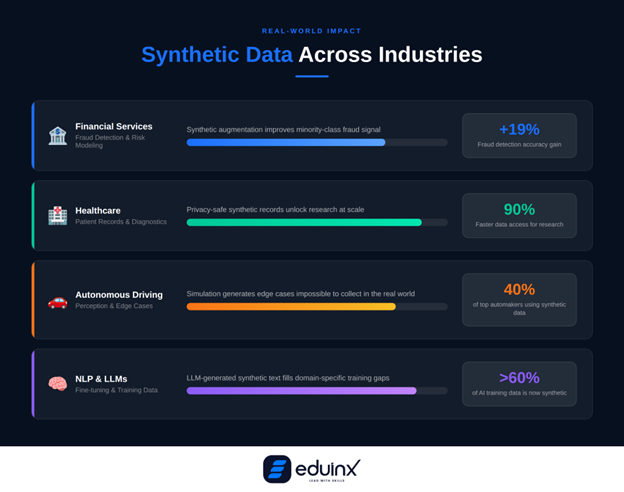
Synthetic data is not a research curiosity. It is already embedded in production pipelines across multiple sectors.
In healthcare, synthetic patient records allow hospitals and research teams to build and test diagnostic models without risking patient privacy. Healthcare applications report a 90% reduction in data access time when using synthetic records for research and model testing, a practical gain that translates directly into faster time-to-insight.
In financial services, synthetic transaction data helps fraud detection models generalize across new fraud patterns that have never appeared in historical records. The reported 19% improvement in fraud identification accuracy from synthetic augmentation has made it a standard practice at many financial institutions.
In autonomous driving, 40% of top-tier automotive manufacturers were already using synthetic data by 2023, with $1.5 billion in projected investment by 2025. Generating millions of simulated driving scenarios, including conditions that would be dangerous or impossible to reproduce in real test drives, is now a prerequisite for building robust perception systems.
In natural language processing, LLMs are increasingly used to generate synthetic training text for fine-tuning smaller, domain-specific models. This covers the gap between general-purpose pre-training data and the domain-specific examples needed for enterprise applications.
What Data Scientists Need to Watch Out For
Synthetic data is not a free pass. There are real failure modes.
Distribution shift is the most common problem. If your generative model does not accurately capture the tails of the real data distribution, the synthetic data will look statistically valid but will underrepresent exactly the edge cases you needed it to cover. Always validate synthetic data against held-out real data using statistical tests, not just visual inspection.
Bias amplification is a subtler risk. If your real dataset has a demographic bias baked in, a generative model trained on that dataset will reproduce and potentially amplify that bias in its synthetic outputs. Synthetic data can fix imbalance, but only if the generation process is explicitly designed to do so.
Overfitting to synthetic data can occur when the synthetic dataset overwhelms the real data in training. The model may achieve high accuracy on both real and synthetic validation data but generalize poorly to unseen real-world inputs. Research from Duke University recommends bias correction procedures during training when mixing real and synthetic data to avoid this failure mode.
MIT researchers studying synthetic data adoption put it plainly: synthetic data holds genuine promise, but using it requires careful evaluation, planning, and checks and balances to prevent performance loss at deployment. For teams building multi-component AI systems at scale, understanding these failure modes requires the same kind of systematic orchestration thinking that applies to managing complexity across intelligent agent pipelines.
🔍 Pro Tip: Always run a fidelity check before training.
After generating a synthetic dataset, run a Train on Synthetic, Test on Real (TSTR) benchmark. Train a model on the synthetic data alone and test it on your real holdout set. If TSTR accuracy is significantly lower than Train on Real, Test on Real (TRTR), your synthetic data has a fidelity problem worth investigating before you invest in full training.
Conclusion
The synthetic data revolution is not coming. It is already here, embedded in the data pipelines of automotive manufacturers, healthcare systems, financial institutions, and AI research labs worldwide. For data scientists, the question is no longer whether synthetic data is reliable enough to use. It is whether you have the skills to use it well.
Understanding when to generate, how to validate, and where the failure modes are will separate practitioners who use synthetic data as a genuine performance tool from those who treat it as an afterthought. The models that will lead their industries in accuracy, fairness, and robustness over the next five years are being trained right now, and a significant portion of their training data does not exist in the real world.



