
AI has transitioned from just creating text to interpreting its significance. One of the reasons for this transformation is Retrieval-Augmented Generation (RAG) — a system that integrates search and generation to yield accurate, contextually informed answers. At the core of RAG is the idea of embeddings, which empower machines to recognize the relationships among words, sentences, and ideas.
are the language of meaning for machines. They allow AI to see relationships between ideas, not just words. Semantic search turns those relationships into actionable insights, and cosine similarity ensures precision in retrieval. Together, they form the backbone of modern AI systems like RAG — enabling smarter, faster, and more reliable answers. As we move forward, mastering these concepts will be key to building AI that truly understands the world, not just describes it.
Embeddings With opportunities booming in the field of AI, having a strong understanding will help you land the right job at an attractive salary package.
What are Embeddings?
Imagine teaching a computer the meaning of "apple." You might show it images, describe it as a type of fruit, or compare it to an "orange." However, computers do not comprehend words; they interpret numbers.
Embeddings serve as the method for transforming words, sentences, or even full documents into numerical forms that encapsulate their meanings. Each word or phrase is represented as a vector — a sequence of numbers that indicates its location in a multi-dimensional space. Here’s a simpler way to put it:
- 1. Words with similar meanings (like king and queen) are close together.
- 2. Words with different meanings (like king and car) are far apart.
Embeddings are like a map of meaning — they tell the computer how close or far concepts are from each other.
How do Embeddings Power Semantic Search?
Traditional search engines depend on keyword matching, which means they search for exact words within documents. However, if you search for "How to fix a leaking tap" and the document states "Repair a dripping faucet," keyword search may overlook it due to the differing terminology.
Semantic search, which utilizes embeddings, addresses this issue. Rather than focusing on word matches, it emphasizes matching meanings. Let us look into how embeddings and semantic search works together.
- Your query: ("How to fix a leaking tap") is transformed into an embedding vector.
- Document conversion: Each document or passage in the database is also assigned its own embedding.
- Comparison: The system then compares the vector of your query with all document vectors to identify those that are closest in meaning.
This proximity is evaluated using similarity metrics, with cosine similarity being the most prevalent.
What is Cosine Similarity?
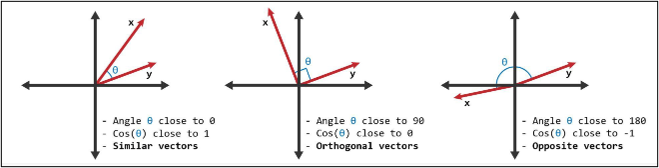
Cosine similarity assesses the alignment of two vectors by computing the cosine of the angle that separates them. It evaluates the degree to which two points or documents are oriented within a multi-dimensional space, regardless of their size or magnitude. In simple terms, cosine similarity tells us how aligned two meanings are.
Think of each vector as an arrow pointing in space. Cosine similarity measures the angle between these arrows:
- Perfect Match: If two arrows point in the same direction, their cosine similarity is 1.
- Completely Different: If they point in opposite directions, it’s –1.
- No Relation: If they’re perpendicular, it’s 0.
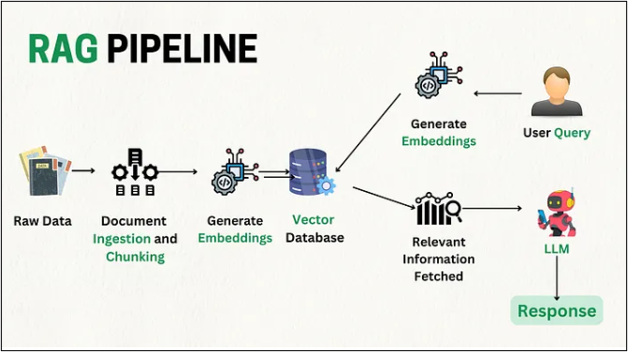
How Does RAG Use Embeddings and Cosine Similarity?
Retrieval-Augmented Generation (RAG) combines search and generation. When you ask a question, RAG doesn’t just rely on its internal knowledge — it retrieves relevant information from external sources before generating an answer. Let us now look into how RAG uses embeddings and cosine similarity.
- Embedding Creation (Process of creation): Your query and all documents are converted into embeddings.
- Semantic Retrieval (Process of finding similarity): The system uses cosine similarity to find documents whose embeddings are closest to your query’s embedding.
- Context Injection (Process of finding relevance): The most relevant documents are passed to the language model as context.
- Answer Generation (Output generation): The model reads the retrieved context and generates a precise, informed answer.
This process ensures that the AI doesn’t “hallucinate” or make up facts — it grounds its responses in real, retrieved data.
Why does Cosine Similarity Matter?
Cosine similarity is the bridge between retrieval and generation. It ensures that the AI retrieves the most semantically relevant information before answering. Here’s a quick brief on how cosine similarity works.
- Precision: It filters out irrelevant data, keeping only the most meaningful context.
- Efficiency: It’s computationally lightweight, making large-scale retrieval fast.
- Scalability: Works well even when comparing millions of document embeddings.
- Accuracy: Improves the quality of generated answers by grounding them in semantically aligned content.
Without cosine similarity, RAG would struggle to distinguish between “apple the fruit” and “Apple the company.” It’s the mathematical glue that holds semantic understanding together.
Real World Applications of Embeddings
Embeddings and cosine similarity aren’t just theoretical — they power many tools you use daily. They help machines understand meaning, not just words.
- Search Engines: Google’s semantic search uses embeddings to understand intent.
- Chatbots: RAG-based assistants retrieve relevant documents before replying.
- Recommendation Systems: Netflix and Spotify use embeddings to suggest similar content.
- Knowledge Management: Enterprises use RAG to query internal documents intelligently.
Future of Semantic Search and RAG
As AI models grow more capable, embeddings will become even richer — capturing not just text meaning but multimodal context (images, audio, and video). Future RAG systems will retrieve across all data types, enabling truly context-aware intelligence. Cosine similarity will remain a cornerstone, but new techniques like vector quantization and approximate nearest neighbor (ANN) search will make retrieval faster and more scalable. The future of AI isn’t just about generating text — it’s about understanding meaning deeply. And that understanding begins with embeddings.
Given that the future will continue to remain bright in this field, there are a plethora of opportunities opening up for both budding and establishment professionals in the field of RAG and generative AI. Being well versed in these concepts will reward you with attractive salary packages and endless perks.
You can learn these concepts through expert guidance at Eduinx, a leading edtech institute in India. Our non academic mentors are here to guide you through a holistic and practical approach in implementing concepts. Whether you are a budding entrepreneur or a working professional, we will help you achieve a phenomenal breakthrough in your career through our expert guidance. Get in touch with our experts to know more.
Frequently Asked Questions
What are the embeddings in AI?
An embedding is a numerical representation of a word, sentence or document that maps it into a multi-dimensional space that represents the meaning of it's. They enable machines to identify relationships among concepts, not just word-to-word matches. In this vector space, words with similar meanings are then grouped. It is the basis for semantic search and RAG systems.
How do embeddings help AI understand meaning?
Embeddings help AI understand meaning by converting language into mathematical vectors. These vectors capture semantic relationships between words and concepts. For example, the word “king” may be closer to “queen” than to “car” because “king” and “queen” are related in meaning. This allows AI systems to compare ideas mathematically and understand user intent, context, and similarity. In simple terms, embeddings help machines understand meaning, not just words.
What is the cosine similarity, in just simple terms?
Cosine similarity calculates an angle between two vectors and measures the closeness of the vectors. With a score of 1 you have a perfect match, 0 means no relation and -1 some opposite meanings. It is broadly utilized because it centres on direction instead of magnitude, so that comparisons are more reliable.
Why does cosine similarity matter in RAG?
Cosine similarity matters in RAG because it helps the system find the most relevant documents for a user’s question. In a RAG pipeline, both the user query and the documents are converted into embeddings. Cosine similarity is then used to compare the query vector with document vectors. The documents with the highest similarity scores are retrieved and passed to the language model as context. This helps the AI generate more accurate, relevant, and grounded answers.
What are the main steps in a RAG pipeline?
Typically, the four elements of a RAG pipeline are: Creating the embedding, semantic retrieval, injecting the context, and generating the answer. First, text is transformed into embeddings, then, the closest matches are found by cosine similarity. The most relevant results are fed as context into the model, that model uses that context to generate its final answer.
What is the process of RAG?
RAG minimizes hallucination by providing the model with retrieved data from the real world instead of solely memorized patterns. Documents are retrieved and given as context before they are generated, which means that the AI itself has information to draw on. This helps to get the exact and verifiable answers.
How do embeddings reduce hallucinations in AI?
Embeddings reduce hallucinations by helping the AI retrieve relevant information before generating an answer. Instead of guessing from memory, the model receives supporting context from documents, knowledge bases, or databases. However, embeddings alone do not completely remove hallucinations. The quality of retrieved documents, ranking logic, prompt design, and evaluation layer also play an important role in improving accuracy.
What does it mean when two vectors have a cosine similarity of 1?
If the cosine similarity is one, then two vectors are pointing exactly the same way, which means that their meanings are nearly the same. This is considered to be the ideal semantic match in retrieval systems. This is the maximum possible similarity score for this metric.
What does cosine similarity equal to 0 mean?
If a cosine similarity is equal to 0, it implies that the two vectors are orthogonal and thus do not have a significant relationship between the two compared entities. For a semantic search, it would appear that the query and the document have little or no context that is relevant. It is used to filter out irrelevant results in systems.
What are the embeddings that Google uses when performing search?
The embedding is basis of the Google's semantic search, enabling the search engine to better understand the goals of a search query instead of just the keywords. This enables it to offer the pertinent results even when the search query term is not contained in the original document. It is one of the ways modern search is able to understand natural language more.
Why are chatbots crucial for using a RAG and embeddings?
RAG based Chatbots record the question received as an embedding, and compare it against the most similar documents in the RAG store using cosine similarity before returning the answer. This will help them to give context-specific and informed answers rather than generic or incorrect ones. In particular for customer support applications and knowledge-base applications.
What does it take to make a career in RAG and Generative AI?
To grasp the basics of RAG and generative AI, you need to familiarize yourself with key concepts like embeddings, semantic search, and cosine similarity. Linking theory and practice can be achieved with a practical training under the guidance of a mentor, e.g. the Eduinx training programs. The field of AI has been rapidly expanding, and there are lucrative career prospects for those who are knowledgeable in the field with competitive salaries.



