Large language models are powerful, but their knowledge comes with an expiry date and are not aware of your internal data. Retrieval-Augmented Generation (RAG) fixes this problem by letting the models look up the information before responding, grounding the outputs in real, current knowledge, rather than relying on training data alone.
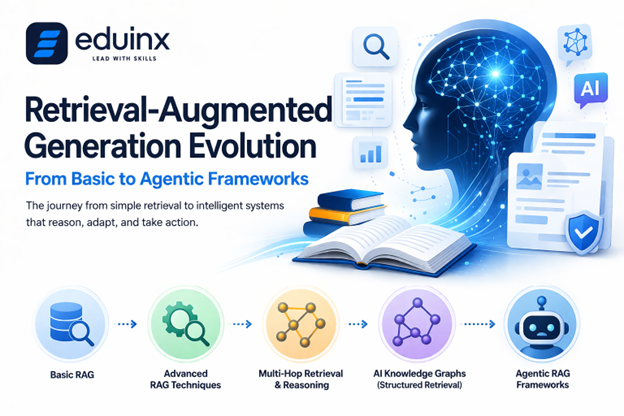
But RAG has not stayed simple for long. In this blog, we trace its full evolution - from basic pipelines to advanced RAG techniques such as multi-hop retrieval, AI knowledge graphs, and neural-symbolic reasoning, all the way to agentic RAG frameworks that lets AI decide what to retrieve, when, and why.
If you are building AI-powered learning tools, this is the architectural journey you need to understand.
Where It All Started: Basic RAG
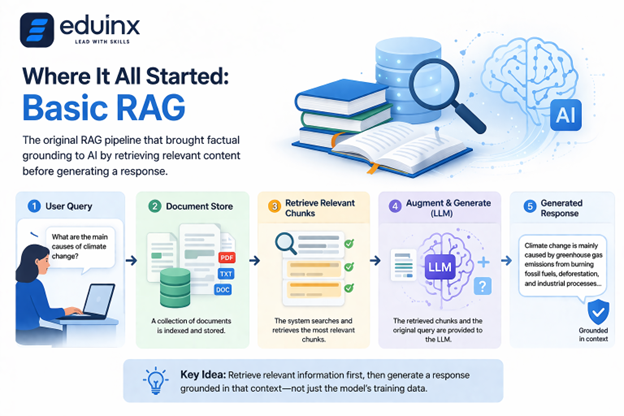
The original RAG pipeline, introduced in a 2020 paper from Facebook AI Research, worked like this: a user sends query which was used to search a document store, the most relevant chunks are retrieved. They are then passed to a language model along with the original question. The model then generates a response grounded in the retrieved context rather than just its training data.
For many use cases, this works well. A student asking a question about a biology textbook chapter, for example, can receive an accurate, sourced answer that the model could not have produced from training alone. Basic RAG brought something genuinely new to the table - factual grounding. If you are new to how RAG fits into the broader generative AI landscape, our explainer on Applied Generative AI: From LLMs to RAG Systems is a good starting point.
But it also had clear ceilings. Retrieval quality heavily depended on how well the user’s query matched the stored content. If a question was phrased differently from how the answer was written, retrieval would fail even when the document existed. And complex, multi-part questions often required information scattered across several sources, which a single retrieval pass could not reliably surface.
"What everybody is doing already seems to work quite well. And we know for a fact that you can do even better."
— Douwe Kiela, Co-inventor of RAG and the CEO of Contextual AI.
Advanced RAG Techniques: Solving the Retrieval Problem
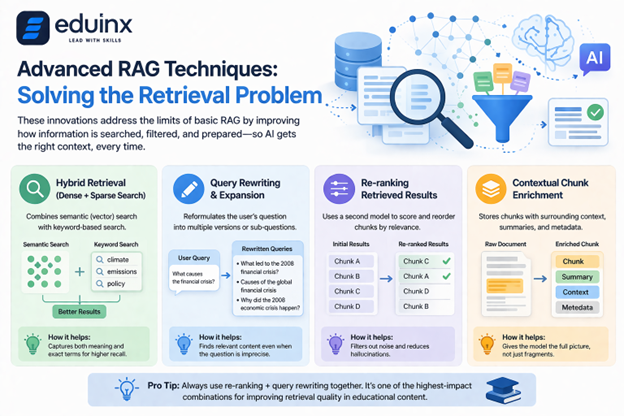
The field responded to these limitations with a wave of advanced RAG techniques that targeted specific failure points in the original design.
One of the most important innovations was hybrid retrieval. Traditional RAG systems rely on dense vector search, embedding both queries and documents into a shared semantic space and finding the closest match. Hybrid retrieval AI models combine this with keyword-based sparse retrieval methods. The result is a system that captures both semantic meaning and exact terminology, which matters enormously in technical and educational contexts where specific terms carry precise meaning.
Another advancement was query rewriting and expansion. Instead of passing the raw user query directly to the retrieval system, an intermediary step reformulates it, generating multiple variations or sub-questions to improve coverage. This is particularly useful in education, where learners often ask imprecise questions that experts would phrase differently.
Re-ranking added a second layer of judgment. After initial retrieval, a separate model scores and reorders the retrieved chunks based on relevance to the specific query, discarding noise before the content reaches the language model. This alone significantly reduces hallucination in systems where retrieval precision matters. One area where these improvements become especially valuable is when RAG is combined with fine-tuning — a topic we break down in detail in LLM Fine-Tuning With RAG: Parameter-Efficient Strategies For Domain Adaptation.
Contextual chunk enrichment also emerged as a key technique. Instead of splitting documents into isolated segments, systems began storing chunks alongside surrounding context, parent document summaries, and structured metadata. This meant that when a chunk was retrieved, the model received enough surrounding information to interpret it correctly rather than working with a fragment stripped of its context.
💡 Pro Tip: Always use re-ranking + query rewriting together. It's one of the highest-impact combinations for improving retrieval quality in educational content. A well-tuned re-ranker catches irrelevant chunks that semantic search lets through, especially when learners use everyday language to ask about technical concepts.
Multi-Hop Retrieval and Reasoning Across Sources
Perhaps the most intellectually interesting development in advanced RAG has been multi-hop retrieval. Real-world questions rarely have single-document answers. A student researching the causes of the 2008 financial crisis, for instance, needs information from economic theory, historical events, regulatory frameworks, and institutional behavior. No single document holds all of this.
Multi-hop retrieval addresses this by treating retrieval as an iterative process. The system retrieves an initial set of documents, uses what it finds to formulate follow-up queries, retrieves again, and continues this process across multiple hops until it has assembled a sufficient evidence base. It mirrors how a skilled researcher actually works, following one lead to the next rather than expecting a single search to surface everything relevant.
This is where RAG began to look less like a database lookup and more like active reasoning. The model was no longer a passive recipient of retrieved context. It was becoming a participant in the retrieval process itself. For teams thinking about how to handle memory and recall across longer interactions, our deep dive on Contextual Memory Trends: Overcoming RAG Limitations For Long-Term AI Recall covers this challenge in more detail.
AI Knowledge Graphs: Adding Structure to Retrieval
Vector databases store information as numeric embeddings, which are excellent for semantic similarity but blind to structured relationships. Two facts might be semantically distant as embeddings but deeply connected as knowledge. This is the problem that AI knowledge graphs were brought in to solve.
Knowledge graph-augmented retrieval layers a structured representation of entities and relationships on top of the traditional vector store. When a query arrives, the system can traverse these relationships explicitly rather than relying on embedding proximity alone. In an educational context, this becomes powerful: a knowledge graph might encode that a concept is a prerequisite for another, that a topic belongs to a curriculum unit, or that a misconception is commonly associated with a particular learning gap. For a closer look at how GraphRAG is being applied across industries, see our coverage of GraphRAG Innovations: Structured Data Boosting LLM Accuracy And Context.
Neural-symbolic retrieval takes this further by combining neural pattern recognition with symbolic logic. The system can both learn from data and reason according to rules, producing outputs that are not just statistically likely but logically coherent. For learning platforms building structured curriculum or assessment tools, this combination is particularly promising. We have also written about how these concepts are coming together in Advanced RAG Architectures: Enhancing LLMs With Knowledge Graphs In 2026, which is worth reading alongside this piece.
💡 Pro Tip: If your ed-tech platform has a defined curriculum structure, encode those prerequisite relationships into a knowledge graph before layering RAG on top. This lets the system surface not just the most semantically similar content, but the most pedagogically appropriate one given where the learner currently is.
Agentic RAG Frameworks: When Retrieval Becomes Action
The most significant shift in the RAG landscape over the past year has been the move toward agentic RAG frameworks. This is not a minor architectural update. It represents a fundamentally different model of how AI systems interact with information.
In a classic RAG pipeline, retrieval is a single, predetermined step. A query comes in, documents come back, a response goes out. Agentic RAG replaces this linear flow with a dynamic loop. The AI model acts as an agent: it decides whether retrieval is needed, what to retrieve, whether the retrieved content is sufficient, whether follow-up retrieval or external tool use is warranted, and when it has enough to generate a reliable answer.
This agent can call multiple tools across a single session. It might retrieve from a course knowledge base, run a calculation, query an external API for real-time data, and check a knowledge graph for conceptual relationships, all in service of answering a single learner question. The system manages its own context, adapts its behavior based on what it finds, and iterates until it reaches confidence in its output. For a practical breakdown of how these autonomous pipelines are actually built, our article on Agentic AI in RAG Systems: Building Autonomous Retrieval and Generation Pipelines goes deeper into the architecture.
"The thing that's really interesting about agentic RAG is you can give AI agent tools to retrieve information and then let it decide... after retrieving the first round of information, is it good enough? Or do you want to do a second round of retrieval?"
— Andrew Ng, Co-founder of Google Brain, Founder of DeepLearning.AI & Coursera
AI context engineering is the discipline that makes this manageable. As agentic systems retrieve and accumulate context across multiple steps, the context window becomes a resource that must be actively managed. Which information to keep, which to compress, which to discard entirely requires deliberate design. Poor context engineering leads to systems that lose track of what they have already found or fail to recognize when they have enough to respond confidently. Real-time data pipelines add another layer of complexity here — something we examine in Operational Data Integration: Real-Time RAG Systems for Enterprise AI.
What This Evolution Means in Practice
The journey from basic RAG to agentic frameworks has been fast by any standard. What began as a relatively straightforward augmentation strategy has grown into a sophisticated ecosystem of retrieval architectures, reasoning patterns, and agent-based orchestration systems.
For teams building AI-powered learning tools, the practical implication is this: the question is no longer whether to use RAG, but which variant of RAG suits the complexity of the problem at hand. Simple document Q&A might be well-served by basic retrieval with good chunking and re-ranking. Multi-domain curriculum tools with complex learner models probably need something closer to an agentic framework with knowledge graph support and multi-hop reasoning.
Understanding where your system sits on this spectrum, and where it needs to go, is now a core competency for anyone working at the intersection of AI and education.
Conclusion
RAG has come a long way from a simple retrieve-and-generate loop. Today, with advanced RAG techniques, knowledge graphs, multi-hop reasoning, and agentic RAG frameworks in the picture, AI systems can reason, adapt, and personalize in ways that were not possible even two years ago. For anyone building learning platforms, understanding this evolution is not optional; it is the foundation every good architectural decision now sits on.



