The first time most teams ship a RAG system, they are thrilled. Documents go in, a vector database stores the embeddings, a user asks a question, and the LLM pulls up something relevant. It feels like magic.
Then production happens.
Users ask questions that span multiple documents, reference obscure relationships, or require the system to connect the dots across data silos. The answers start falling apart: retrieved chunks miss the point, hallucinations creep in, and trust erodes fast. This is where building AI agents with RAG and LangChain stops being a prototype exercise and becomes a serious architecture problem.
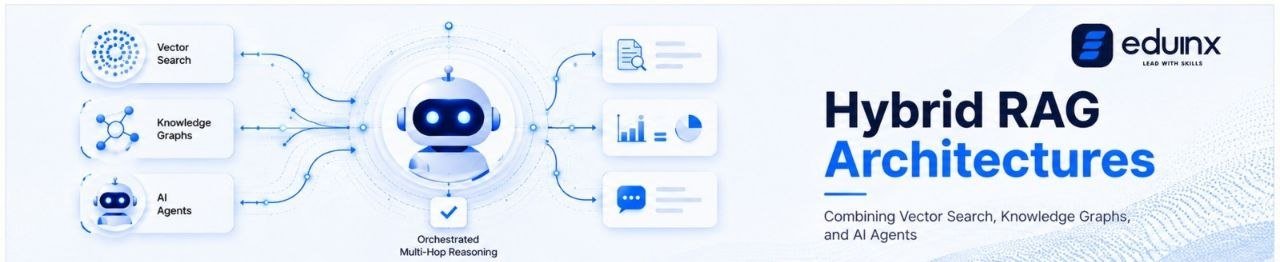
The answer is hybrid RAG: a multi-layer approach that combines vector search, knowledge graphs, and AI agents into a single, production-grade retrieval pipeline.
Why Naive RAG Fails at Scale

Standard vector-only RAG encodes documents into dense embeddings and retrieves the top-K chunks most semantically similar to the user's query. That works well for "find me the paragraph that talks about X." It breaks down the moment the question needs relational reasoning.
Consider an enterprise support scenario: "Has this client encountered this error in another department, and how was it resolved previously?" A vector search will retrieve tickets that mention the error. But connecting the client entity across departments, products, and time periods requires something a flat chunk index simply cannot do.
Research from production deployments in 2024 showed that hybrid search combining dense semantic retrieval with sparse keyword methods like BM25 consistently outperforms either approach alone, with Reciprocal Rank Fusion (RRF) delivering 15-30% better retrieval accuracy than pure vector search. That gap matters at enterprise scale: a 15% improvement in retrieval precision translates directly into fewer hallucinations and higher user trust.
The deeper problem is the semantic gap. User queries are often short and vague ("Q3 anomalies"), while documents are dense and specific. Production RAG systems increasingly address this mismatch through multi-stage pipelines that layer hybrid search on top of vector retrieval, combined with a post-retrieval reranking step to improve top-K precision.
Neither fix is enough on its own. The real architectural leap comes from adding a third retrieval layer: the knowledge graph.
💡 Pro Tip: Start with the "Three Hops" Test. Before deciding whether your team needs a knowledge graph layer, ask: does answering your users' questions require connecting information from more than three separate documents or data sources? If yes, a graph-based retrieval layer will pay for itself quickly. If your queries are self-contained within single documents, optimized vector search with reranking may be sufficient for now.
Knowledge Graph RAG: Why Relationships Change Everything

A knowledge graph represents data as a network of entities and relationships, not a collection of text chunks. When you model your knowledge domain as a graph, you enable a qualitatively different kind of retrieval: instead of asking "what text is similar to this query?", you ask "what entities are connected to this concept, and how?"
GraphRAG, popularized by a 2024 Microsoft Research paper, uses a knowledge graph as the retrieval layer for an LLM rather than a flat vector index. The core intuition is straightforward: instead of retrieving semantically similar text chunks, the system retrieves connected knowledge from a graph and provides that richer context to the model.
This matters because relationships carry meaning that embeddings lose. If a document says "Company A acquired Company B, which manufactures Component C used in Product D," a vector search for "Product D supply chain" may or may not retrieve the acquisition document depending on how it was chunked. A knowledge graph traversal starting from "Product D" will reliably surface the entire chain: component, manufacturer, parent company, acquisition date.
For enterprise AI in 2024-2025, the adoption of Graph RAG has been driven by the need to move generative AI from a creative assistant role to a trusted analyst: one that delivers transparent reasoning paths showing exactly which entities and relationships were traversed to produce an answer, which is essential for compliance.
The practical architecture looks like this: queries first hit the knowledge graph to identify relevant entities and relationships, then vector search retrieves the supporting text chunks for those entities, and finally the LLM synthesizes both into a grounded answer.
"The graph doesn't replace vector search, it guides it. You use graph traversal to identify the right neighborhood of knowledge, then dense retrieval to find the most relevant passages within that neighborhood."
- Tomaz Bratanic, Developer Advocate at Neo4j (via Neo4j Developer Blog)
Building the Pipeline with LangChain
LangChain has become the default orchestration layer for teams building Knowledge Graph RAG pipelines. With approximately 119,000 GitHub stars and over 500 integrations, it remains the most widely adopted RAG orchestration framework. Its extension LangGraph adds stateful multi-agent workflows, making the combination the go-to starting point for agentic systems where RAG is one capability among many.
In practice, a LangChain Knowledge Graph RAG pipeline connects Neo4j or a similar graph database, an embedding model, and an LLM through a retrieval chain that first runs a Cypher query against the graph, then performs vector similarity search on the resulting subgraph, then passes the combined context to the generation step.
AI Agents: The Orchestration Layer That Ties It Together
Once you have both a vector store and a knowledge graph, you need something to decide when to use each, how to combine their outputs, and when to loop back and search again if the first retrieval attempt falls short. That something is an AI agent.
An agentic RAG system treats retrieval as a tool-use problem. The agent receives a query, formulates a retrieval plan, calls the appropriate tools (vector search, graph query, or both), evaluates the results, and decides whether to generate an answer or re-query with a refined approach. This is fundamentally different from a static pipeline where retrieval always follows the same fixed steps.
Gartner projects that by 2028, 33% of enterprise software applications will include agentic AI, up from less than 1% in 2024, enabling 15% of day-to-day work decisions to be made autonomously. The retrieval problem is one of the first places agentic intelligence earns its keep: an agent that routes relationship-heavy queries to graph traversal and semantic queries to vector search consistently outperforms any static hybrid pipeline.
The agent also handles failure gracefully. If the initial graph query returns too few results, the agent widens its traversal depth. If vector search returns irrelevant chunks, the agent rephrases the query and retries. Static pipelines silently return bad results; agentic pipelines recover.
When building AI agent frameworks for enterprise search, treat the retrieval decision itself as a reasoning step. Give your agent explicit tools for graph query, vector search, keyword search, and metadata filtering, then let it plan the retrieval sequence based on query type.
Enterprise RAG Solutions: What Production Actually Looks Like

By 2026, 85% of enterprises are projected to adopt hybrid RAG systems combining vector and graph databases to balance speed and depth, with startups already achieving 92% accuracy in legal document analysis using Knowledge Graph RAG.
The adoption momentum is real, but so are the implementation challenges. Most teams underestimate three things: graph schema design, the cost of entity extraction at scale, and the observability requirements for agentic pipelines.
Entity extraction at scale involves parsing entities and relationships from existing enterprise documents using an LLM with structured output. It becomes expensive and introduces its own error rate. Teams that succeed here invest in validation workflows where domain experts spot-check extraction quality before data enters the graph.
On observability: according to Forrester's 2025 analysis, RAG has become the default architecture for enterprise knowledge assistants, with agentic orchestration and graph-aware retrieval now essential for maintaining trust at scale. Tools like LangSmith and evaluation frameworks like RAGAS provide the instrumentation layer that separates a prototype from a system users will actually rely on.
The organizations seeing the strongest ROI share one pattern: start narrow, instrument everything from day one, and expand the graph schema iteratively as you discover which entity relationships drive the most retrieval failures.
For teams building enterprise AI systems, understanding the governance dimension is equally important. The responsible AI governance frameworks shaping enterprise deployments in 2026, from NIST AI RMF to EU AI Act requirements, directly apply to RAG systems that retrieve and synthesize sensitive data in finance, healthcare, and legal domains.
Conclusion
Hybrid RAG is not a single technology. It is a design philosophy: use the right retrieval mechanism for each type of question, orchestrate them intelligently with an AI agent, and build in the observability to know when the system is failing and why. Vector search handles semantic similarity. Knowledge graphs handle relationships and multi-hop reasoning. AI agents tie the two together.
RAG framework adoption has surged 400% since 2024, with 60% of production LLM applications now using retrieval-augmented generation, and organizations implementing RAG reporting 25-30% reductions in operational costs and 40% faster information discovery. Understanding the generative AI ethics and governance principles that underpin trustworthy systems is the final piece of that puzzle.
The gap between a proof-of-concept RAG demo and a production system your organization trusts is almost always a retrieval architecture problem. Hybrid RAG, built thoughtfully and instrumented properly, is how you close that gap.
Frequently Asked Questions (FAQs)
1. What does hybrid RAG mean and what is the difference between hybrid RAG and normal RAG?
Standard RAG only finds semantically similar text chunks and is limited when you need to link information from different documents or data sources. In production, Hybrid RAG achieves 15-30% higher retrieval accuracy and far fewer hallucinations thanks to its multi-layer pipeline of vector search, keyword search (such as BM25), knowledge graph and AI agents.
2. What is the reason for RAG to fail in production in enterprise applications?
Naive vector-only RAG fails when users ask questions that span multiple documents, when users want the RAG to have relational reasoning, or when users want to connect entities between data silos. Also faces the semantic gap: short vague queries, dense documents, causing irrelevant retrievals, missing context, and hallucinations, rapidly losing the user's trust.
3. What is Knowledge Graph RAG (GraphRAG), and how can I use it?
Knowledge Graph RAG (popularised by Microsoft Research in 2024) uses a graph of entities and relationships as the retrieval layer instead of a flat vector index. Use it when your users ask multi-hop questions that require tracing connections - like supply chains, client histories, or regulatory dependencies - where vector search alone would miss the relational context.
4. What are the benefits of using AI agents for RAG retrieval pipelines?
AI agents interpret retrieval as a tool-use problem, and based on the type of query, they determine whether or not to use vector search, graph traversal, or keyword search, and then evaluate the results and retry using a different approach if the initial query does not succeed. Unlike static pipelines that silently return bad results, agentic pipelines self-correct and consistently outperform fixed retrieval sequences.
5. What are the biggest challenges when deploying hybrid RAG in an enterprise?
The three most underestimated challenges are: designing the graph schema correctly upfront, the cost and error rate of LLM-powered entity extraction at scale, and setting up observability for agentic pipelines. Teams that succeed invest in domain expert validation for entity extraction and instrument everything from day one using tools like LangSmith and evaluation frameworks like RAGAS.


Rishabh Dev Choudhary
Share on Social Platform:
Subscribe to Our Newsletter
Recommended Articles

AI Product Managers: Roles, Responsibilities, and Future Scope
Did you know that a highly skilled product manager has the ability to increase
Learn More

Generative AI: A Deep Dive
Did you know that 75% of gen AI users are looking to
Learn More